I’ve recently been working a little on whether consistency across different questions can be used as a measure of (and perhaps ultimately as a training target for) philosophical competence. I’m in the process of writing up the results into a paper. I’m here reporting results from a small, preliminary experiment that I ran late last year. I’ll leave a more careful discussion (with a proper introduction, related work and so on) to that paper. I’ll also take it for granted that it’s valuable to make models good at philosophy and such. (My colleagues and I will write more about this soon.)
What I mean by consistency. By consistency, I mean properties like this: If you ask a (prompted/fine-tuned/scaffolded) model two equivalent versions of the same question, it’ll give similar answers on average over multiple samples. The experiments I report here are based just on this type of equality-on-average constraints. But it’s not that difficult to come up with other types of constraints between prompts. (E.g., consider the following two questions: (1) “How confident are you that one should one-box in Newcomb’s problem?” (2) “How confident are you that evidential decision theory (EDT) is correct?” Taking for granted that EDT implies one-boxing, the model should give a higher confidence for 1 than 2.)
Why consistency for philosophical competence. In general, making models better at philosophy (and other conceptual topics) is constrained by the lack of reliable, scalable reward/evaluation signals. For example, it’s unclear whether insects are conscious, whether evidential or logical-causality-based approaches to Newcomb-like decision problems are more promising, etc. So it’s very unclear how to reward models for how they respond to such questions.
The hope for consistency is that it can serve as a reliable, scalable reward signal. For reliability: While we are uncertain and often in disagreement about conceptual questions (and thus typically struggle to find reliable rewards for individual responses), we are often confident and in agreement about consistency relationships across prompts. For scalability: Note that many forms of consistency can probably be checked fully automatically using the models themselves. For instance, one can get current LLMs to automatically generate questions and paraphrases of those questions. (One might even hope that other consistency tests – e.g., ones based on facts of probability like P(A) ≥ P(A and B) – can be generated without even LLMs.) Especially if the question asks for structured output (probabilities, multiple-choice), we can automatically assess whether model responses are consistent across these prompts.
Central research question: How good of a reward signal is consistency in conceptual domains? In my mind the main doubt about consistency is how valuable it is in practice as a reward/eval signal for the kinds of tasks we care about. Of course, some forms of consistency (e.g., non-sycophancy) are intrinsically valuable. More ambitiously, however, one might hope that one could optimize a model to be consistent on philosophical issues and thereby make it broadly more competent at reasoning about philosophy (e.g., making it think through the issues more carefully, etc.). My main uncertainty about consistency is to what extent this hope can materialize (for the kinds of domains I’d like to make the models better at). I here document a preliminary test of this.
Rewrite consistency versus competence on the LMCA dataset
High-level experimental setup. Here’s the experiment. I used the LMCA dataset as a starting point. (For the following, I’ll assume familiarity with the basic structure of that dataset.)
I created simple rewrites of critiques by slightly changing the wording. I prompted models to generate these rewrites, but I hand-approved them. I created 398 such rewrites.
I then correlate two quantities:
- A model’s loss on the LMCA dataset (how good is the model at approximating human judgements?);
- A model’s consistency w.r.t. to rewrites.
The measure of consistency that I use is basically an unbiased estimate of the mean-squared difference, normalized against the model’s overall variance on the data set. I describe this in more detail in the “Experimental details” section below. To get somewhat accurate estimates, I sample 20 to 40 responses for each paraphrasing (varying the amount per judge to sample more for higher-variance judges).
As the regular LMCA loss, I use the “weighted pairwise ranking error rate” described in our preliminary LMCA write-up in what is currently Appendix B.1. In general this is one of my favorite loss functions for this dataset (for reasons described to some extent in that writeup). For this specific purpose one important property of it is (I think) that it doesn’t punish range compression. In principle, a model can score all critiques between 0.1 and 0.2 and still get a loss of 0 in terms of this metric.
Are more competent models more consistent? I ran this experiment using a bunch of different models (~all the OpenAI, Gemini, and Anthropic models) with the same prompt. Note that regular LMCA scores correlate closely with generic capabilities. So this experiment can be viewed as testing whether generically more competent models are also more consistent in rating critiques in conceptual domains.
Here’s the result (n=32):
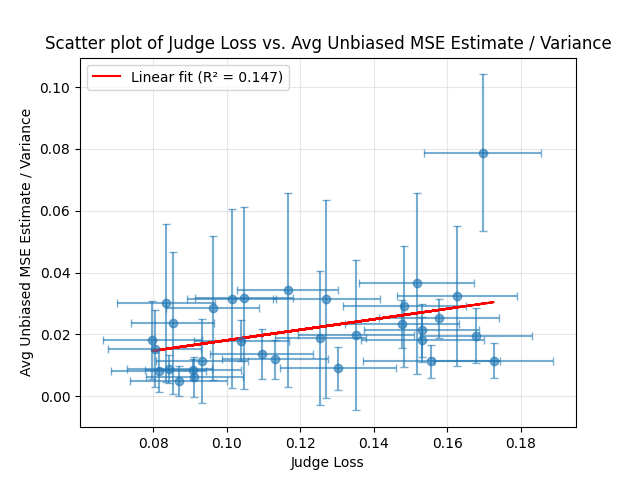
I have removed one outlier in Qwen3-30B-A3B-Instruct-2507, which has a loss of 0.14 but is about ten times as inconsistent as the next-inconsistent model. (I give correlations and p values both with and without the outlier below.)
The y axis is our measure of consistency (again, see below for details), where higher is worse (less consistent). Judge loss is the model’s loss at the regular LMCA task. So higher is worse on both dimensions of the plot. The lines attached to the plots denote 90% confidence intervals.
The Pearson correlation between judge loss and inconsistency is: 0.38 (p=0.030)
Spearman rank correlation: 0.36 (p=0.042)
With the outlier: Pearson 0.19 (p=0.30), Spearman 0.35 (p=0.046).
Overall my sense from this is that better models are more consistent, but the evidence just from the above isn’t super strong. From looking at some of the individual data points, I’m pretty sure that there can’t be a very strong/reliable correlation. For instance, GPT 4.1 Nano is one of the most consistent models (with relatively high sample sizes and small confidence intervals).
Do competence-inducing prompts also induce greater consistency? I also ran this experiment with GPT 5 Nano under different prompts and temperature parameters. The prompts are randomly generated from a given set of expert-written instructions and expert-curated few-shot examples, and the temperature is chosen uniformly at random from [0,1]. (Varying temperature along with prompts was arguably a mistake, because one might have various relatively uninteresting hypotheses about the effect of temperature. I don’t think these explain the results, though – see below.) So this asks: Are prompts that make GPT 5 Nano consistent also good at making GPT 5 Nano competent? In my mind this is more important than the above, because varying the prompt and the temperature parameters is a tractable intervention. You can view this asking: if we train on consistency, do we make the model more competent? Only the “training” being used is extremely crude (trying different prompts and temperature parameters at random and then taking the best).
Here are the current results (n: 116):

Pearson correlation: 0.24 (p-value: 0.0095)
Spearman correlation: 0.28 (p-value: 0.0024)
I omitted confidence intervals from this plot, because the confidence intervals would cover up the entire plot. The confidence intervals are all quite large on both axes, though – something like 0.01 on the consistency axis and 0.015 on the regular judge loss. So basically all the confidence intervals overlap.
From the p value and looking at the plot, the evidence from this experiment seems quite strong: there seems to be a correlation between consistency and judge ability. It’s also clear that at the current sample sizes the correlation is quite weak. It remains an open question whether scaling the number of samples and the number of questions can turn consistency into a more reliable (higher-correlation) signal of competence.
How much is the result driven by varying temperature (as opposed to varying prompts)? Probably not at all: Temperature is statistically insignificantly positively correlated with judge loss and statistically insignificantly negatively correlated with our measure of inconsistency.
I also ran the same experiment with Haiku 3, n=105 judges – unfortunately with incomplete results, since Haiku 3 is retired:
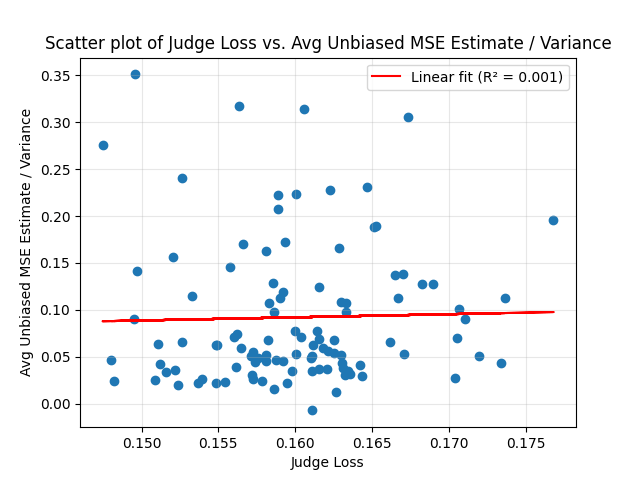
Pearson: 0.027 (p-value: 0.78)
Spearman: 0.13 (p-value: 0.19)
The correlation is still positive, but both from the p values and from looking at the graph, the evidence from this result alone isn’t very persuasive. Alas, I have no way of gathering more data for this model and we’ll never know whether the correlation found in GPT 5 Nano could also be obtained in Haiku 3.
Experimental detail: How I measure consistency
The short version is that for each pair of critiques that only differ by being rephrased, we obtain an unbiased estimate of (x-y)^2, where x and y are the expected overall scores that the model gives to the two critiques. And then we just aggregate this across groups of equivalent critiques. Finally, I divide by the judge’s variance across the whole regular dataset. So in some sense I’m measuring: How much does the judge vary between equivalent critiques versus how much does it vary between critiques in our datasets (which presumably mostly aren’t equally good).
More detail: Basically the same as what’s described in Appendix A here: https://www.andrew.cmu.edu/user/coesterh/LLMxSG.pdf Mostly copied from there, adapting slightly to the present context:
We want to measure some notion of the distance between two stochastic policies. In particular, it seems most natural to care about the absolute difference (or mean squared difference) between the means of the policies.
What makes this difficult is that we can typically only sample from the distributions we are trying to compare. So, in general, we face the following challenge. We have two random variables X and Y (with domain [0,1], representing how the model responds to a specific critique and its rewrite. We are interested in (E[X] − E[Y])^2 as a measure of how different the model’s behavior differs between the two.
(Why not |E[X] − E[Y]|? This is purely for technical reasons. As we show in the following, we can compute unbiased estimates of (E[X] − E[Y])^2. I’m pretty sure that no analogous unbiased estimator exists for |E[X] − E[Y]|.)
Naively, one might simply estimate E[X] and E[Y] by taking the sample average, and then calculate the squared difference of these estimates. Unfortunately, while the sample average is an unbiased estimator of the expected value, the squared difference of the sample averages is a biased estimate of the squared difference. In particular, it’s generally an overestimate. This is easy to see in the case where E[X] = E[Y]. Unless X, Y are degenerate, we’ll typically find that the squared difference of the sample means will be positive and thus an overestimate.
It turns out that an unbiased estimator can be constructed by taking the naive squared difference of the sample means and subtracting (Var(X) + Var(Y))/n, where n is the number of samples. (The derivation isn’t complicated, see the aforelinked paper.) Of course, we don’t know the true variances of X and Y, but we can obtain an unbiased estimate of the variance as long as we have at least two samples.
Note that this unbiased estimator can be negative (whereas the term it is estimating is always nonnegative).
Now we’re slightly extending this metric. One problem for us is that one way to achieve good consistency as judged by the above is by always giving ~the same rating in general. This is especially important in the context of experiments based on randomly generated prompts. E.g., some of the randomly generated prompts will only contain few-shot examples with very low overall ratings and so those prompts might result in a very good consistency score. We address this by changing the consistency metric by normalizing by the variance in overall scores across the whole dataset. I’m pretending that we can calculate this variance perfectly, given that we have so many data points.
I find this normalization very intuitive. It’s also reminiscent of a lot of common loss/objective functions in ML, e.g., objectives in clustering, “maximum-margin”-type objectives for classification. All of that said, it does still have some possible issues. For instance, one issue is that normalizing by the variance across the whole dataset would reward models for increasing their variance, including in ways that don’t make it more challenging to be consistent across rewrites. For instance, giving scores of 0 and 1 a lot increases variances, but if anything might make it easier to be consistent across rewrites.
