A blog on Philosophy, Artificial Intelligence and Effective Altruism
Author: Caspar
I am a Computer Science PhD student at Carnegie Mellon University, most interested in decision and game theory as they relate to future artificial intelligence systems.
I’ve recently been working a little on whether consistency across different questions can be used as a measure of (and perhaps ultimately as a training target for) philosophical competence. I’m in the process of writing up the results into a paper. I’m here reporting results from a small, preliminary experiment that I ran late last year. I’ll leave a more careful discussion (with a proper introduction, related work and so on) to that paper. I’ll also take it for granted that it’s valuable to make models good at philosophy and such. (My colleagues and I will write more about this soon.)
What I mean by consistency. By consistency, I mean properties like this: If you ask a (prompted/fine-tuned/scaffolded) model two equivalent versions of the same question, it’ll give similar answers on average over multiple samples. The experiments I report here are based just on this type of equality-on-average constraints. But it’s not that difficult to come up with other types of constraints between prompts. (E.g., consider the following two questions: (1) “How confident are you that one should one-box in Newcomb’s problem?” (2) “How confident are you that evidential decision theory (EDT) is correct?” Taking for granted that EDT implies one-boxing, the model should give a higher confidence for 1 than 2.)
Why consistency for philosophical competence. In general, making models better at philosophy (and other conceptual topics) is constrained by the lack of reliable, scalable reward/evaluation signals. For example, it’s unclear whether insects are conscious, whether evidential or logical-causality-based approaches to Newcomb-like decision problems are more promising, etc. So it’s very unclear how to reward models for how they respond to such questions.
The hope for consistency is that it can serve as a reliable, scalable reward signal. For reliability: While we are uncertain and often in disagreement about conceptual questions (and thus typically struggle to find reliable rewards for individual responses), we are often confident and in agreement about consistency relationships across prompts. For scalability: Note that many forms of consistency can probably be checked fully automatically using the models themselves. For instance, one can get current LLMs to automatically generate questions and paraphrases of those questions. (One might even hope that other consistency tests – e.g., ones based on facts of probability like P(A) ≥ P(A and B) – can be generated without even LLMs.) Especially if the question asks for structured output (probabilities, multiple-choice), we can automatically assess whether model responses are consistent across these prompts.
Central research question: How good of a reward signal is consistency in conceptual domains? In my mind the main doubt about consistency is how valuable it is in practice as a reward/eval signal for the kinds of tasks we care about. Of course, some forms of consistency (e.g., non-sycophancy) are intrinsically valuable. More ambitiously, however, one might hope that one could optimize a model to be consistent on philosophical issues and thereby make it broadly more competent at reasoning about philosophy (e.g., making it think through the issues more carefully, etc.). My main uncertainty about consistency is to what extent this hope can materialize (for the kinds of domains I’d like to make the models better at). I here document a preliminary test of this.
Rewrite consistency versus competence on the LMCA dataset
High-level experimental setup. Here’s the experiment. I used the LMCA dataset as a starting point. (For the following, I’ll assume familiarity with the basic structure of that dataset.)
I created simple rewrites of critiques by slightly changing the wording. I prompted models to generate these rewrites, but I hand-approved them. I created 398 such rewrites.
I then correlate two quantities:
A model’s loss on the LMCA dataset (how good is the model at approximating human judgements?);
A model’s consistency w.r.t. to rewrites.
The measure of consistency that I use is basically an unbiased estimate of the mean-squared difference, normalized against the model’s overall variance on the data set. I describe this in more detail in the “Experimental details” section below. To get somewhat accurate estimates, I sample 20 to 40 responses for each paraphrasing (varying the amount per judge to sample more for higher-variance judges).
As the regular LMCA loss, I use the “weighted pairwise ranking error rate” described in our preliminary LMCA write-up in what is currently Appendix B.1. In general this is one of my favorite loss functions for this dataset (for reasons described to some extent in that writeup). For this specific purpose one important property of it is (I think) that it doesn’t punish range compression. In principle, a model can score all critiques between 0.1 and 0.2 and still get a loss of 0 in terms of this metric.
Are more competent models more consistent? I ran this experiment using a bunch of different models (~all the OpenAI, Gemini, and Anthropic models) with the same prompt. Note that regular LMCA scores correlate closely with generic capabilities. So this experiment can be viewed as testing whether generically more competent models are also more consistent in rating critiques in conceptual domains.
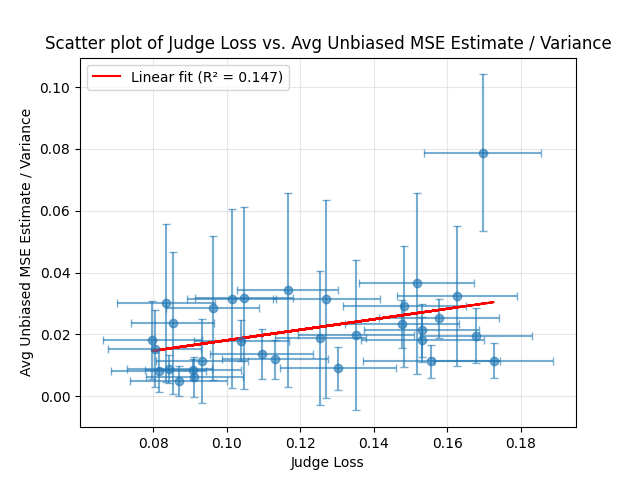
Here’s the result (n=32):
I have removed one outlier in Qwen3-30B-A3B-Instruct-2507, which has a loss of 0.14 but is about ten times as inconsistent as the next-inconsistent model. (I give correlations and p values both with and without the outlier below.)
The y axis is our measure of consistency (again, see below for details), where higher is worse (less consistent). Judge loss is the model’s loss at the regular LMCA task. So higher is worse on both dimensions of the plot. The lines attached to the plots denote 90% confidence intervals.
The Pearson correlation between judge loss and inconsistency is: 0.38 (p=0.030) Spearman rank correlation: 0.36 (p=0.042)
With the outlier: Pearson 0.19 (p=0.30), Spearman 0.35 (p=0.046).
Overall my sense from this is that better models are more consistent, but the evidence just from the above isn’t super strong. From looking at some of the individual data points, I’m pretty sure that there can’t be a very strong/reliable correlation. For instance, GPT 4.1 Nano is one of the most consistent models (with relatively high sample sizes and small confidence intervals).
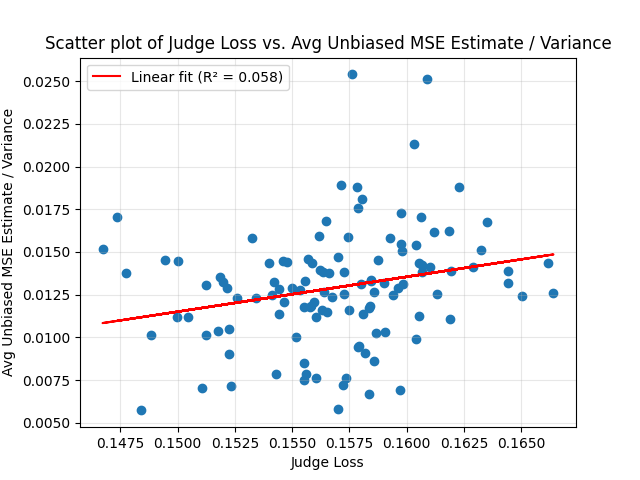
Do competence-inducing prompts also induce greater consistency? I also ran this experiment with GPT 5 Nano under different prompts and temperature parameters. The prompts are randomly generated from a given set of expert-written instructions and expert-curated few-shot examples, and the temperature is chosen uniformly at random from [0,1]. (Varying temperature along with prompts was arguably a mistake, because one might have various relatively uninteresting hypotheses about the effect of temperature. I don’t think these explain the results, though – see below.) So this asks: Are prompts that make GPT 5 Nano consistent also good at making GPT 5 Nano competent? In my mind this is more important than the above, because varying the prompt and the temperature parameters is a tractable intervention. You can view this asking: if we train on consistency, do we make the model more competent? Only the “training” being used is extremely crude (trying different prompts and temperature parameters at random and then taking the best).
I omitted confidence intervals from this plot, because the confidence intervals would cover up the entire plot. The confidence intervals are all quite large on both axes, though – something like 0.01 on the consistency axis and 0.015 on the regular judge loss. So basically all the confidence intervals overlap.
From the p value and looking at the plot, the evidence from this experiment seems quite strong: there seems to be a correlation between consistency and judge ability. It’s also clear that at the current sample sizes the correlation is quite weak. It remains an open question whether scaling the number of samples and the number of questions can turn consistency into a more reliable (higher-correlation) signal of competence.
How much is the result driven by varying temperature (as opposed to varying prompts)? Probably not at all: Temperature is statistically insignificantly positively correlated with judge loss and statistically insignificantly negatively correlated with our measure of inconsistency.
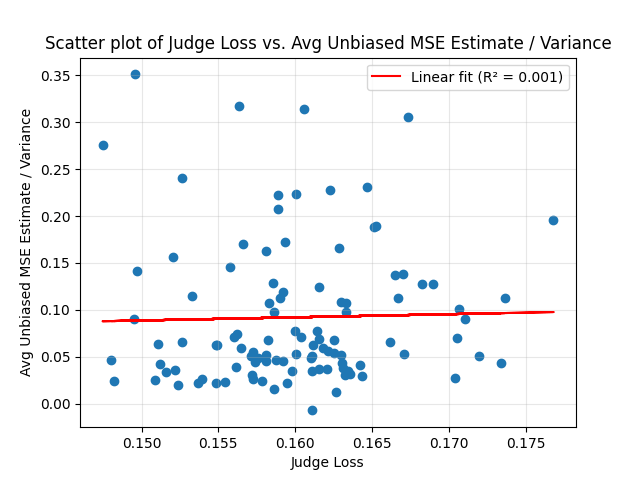
I also ran the same experiment with Haiku 3, n=105 judges – unfortunately with incomplete results, since Haiku 3 is retired:
The correlation is still positive, but both from the p values and from looking at the graph, the evidence from this result alone isn’t very persuasive. Alas, I have no way of gathering more data for this model and we’ll never know whether the correlation found in GPT 5 Nano could also be obtained in Haiku 3.
Experimental detail: How I measure consistency
The short version is that for each pair of critiques that only differ by being rephrased, we obtain an unbiased estimate of (x-y)^2, where x and y are the expected overall scores that the model gives to the two critiques. And then we just aggregate this across groups of equivalent critiques. Finally, I divide by the judge’s variance across the whole regular dataset. So in some sense I’m measuring: How much does the judge vary between equivalent critiques versus how much does it vary between critiques in our datasets (which presumably mostly aren’t equally good).
We want to measure some notion of the distance between two stochastic policies. In particular, it seems most natural to care about the absolute difference (or mean squared difference) between the means of the policies.
What makes this difficult is that we can typically only sample from the distributions we are trying to compare. So, in general, we face the following challenge. We have two random variables X and Y (with domain [0,1], representing how the model responds to a specific critique and its rewrite. We are interested in (E[X] − E[Y])^2 as a measure of how different the model’s behavior differs between the two.
(Why not |E[X] − E[Y]|? This is purely for technical reasons. As we show in the following, we can compute unbiased estimates of (E[X] − E[Y])^2. I’m pretty sure that no analogous unbiased estimator exists for |E[X] − E[Y]|.)
Naively, one might simply estimate E[X] and E[Y] by taking the sample average, and then calculate the squared difference of these estimates. Unfortunately, while the sample average is an unbiased estimator of the expected value, the squared difference of the sample averages is a biased estimate of the squared difference. In particular, it’s generally an overestimate. This is easy to see in the case where E[X] = E[Y]. Unless X, Y are degenerate, we’ll typically find that the squared difference of the sample means will be positive and thus an overestimate.
It turns out that an unbiased estimator can be constructed by taking the naive squared difference of the sample means and subtracting (Var(X) + Var(Y))/n, where n is the number of samples. (The derivation isn’t complicated, see the aforelinked paper.) Of course, we don’t know the true variances of X and Y, but we can obtain an unbiased estimate of the variance as long as we have at least two samples.
Note that this unbiased estimator can be negative (whereas the term it is estimating is always nonnegative).
Now we’re slightly extending this metric. One problem for us is that one way to achieve good consistency as judged by the above is by always giving ~the same rating in general. This is especially important in the context of experiments based on randomly generated prompts. E.g., some of the randomly generated prompts will only contain few-shot examples with very low overall ratings and so those prompts might result in a very good consistency score. We address this by changing the consistency metric by normalizing by the variance in overall scores across the whole dataset. I’m pretending that we can calculate this variance perfectly, given that we have so many data points.
I find this normalization very intuitive. It’s also reminiscent of a lot of common loss/objective functions in ML, e.g., objectives in clustering, “maximum-margin”-type objectives for classification. All of that said, it does still have some possible issues. For instance, one issue is that normalizing by the variance across the whole dataset would reward models for increasing their variance, including in ways that don’t make it more challenging to be consistent across rewrites. For instance, giving scores of 0 and 1 a lot increases variances, but if anything might make it easier to be consistent across rewrites.
Let’s say we want to identify effective strategies for multi-agent games like the Iterated Prisoner’s Dilemma or more complex environments (like the kind of environments in Melting Pot). Then tournaments are a natural approach: let people submit strategies, and then play all these strategies against each other in a round-robin tournament.
But there’s a question of what to do with these results and in particular how to reward participants for their strategies’ success. The most principled approach would be to reward participants in direct proportion to the utility they obtain. If your strategy earns 100 units of utility across interactions with all opponents, you get $100.
Unfortunately, this principled scheme is not very practical.1 Instead, I think tournaments will usually give ranking-based rewards. Alex Mennen and I gave a monetary reward to the top-ranked strategy in our respective tournaments. Axelrod didn’t hand out monetary rewards, but dedicated quite a lot of attention in his book to the top-ranking strategy (or strategies) (crediting Anatol Rapoport for submitting it).
Unfortunately, ranking-based rewards come with a number of problems. One (known) problem is that if you only reward the top (say, top three) programs, high-risk strategies might become more attractive than their expected utility would suggest. (It might be better to get, say, a utility of 100 for 1st place with 10% probability and a utility of 0 for bottom place with 90% probability, than to reliably get a reward of 90 for a ranking between 10 and 20.)2
I here want to focus on a different issue with ranking-based rewards: they create perverse incentives for spiteful or over-competitive behavior. Another’s failure might be your gain, if it makes the other participant fall below you in the rankings. For example, imagine we’re running an Iterated Prisoner’s Dilemma tournament with the following twist. Let’s say that occasionally players get an opportunity to inflict at no cost to themselves a large negative payoff (say, -100) on their opponent in a way that’s undetectable to the opponent (and thus unpunishable). In a normal utility-based framework, there’s no reason to take this action. However, under ranking-based rewards, you would always want to take this spiteful action. Decreasing your opponent’s total utility across the tournament might lower their ranking below yours and thus improve your position in the final standings. Perhaps even more troublingly, for small enough epsilon, you’d be willing to sacrifice epsilon units of your own reward just to inflict this large negative payoff on your opponent.3
There is a relatively simple solution to this spite problem, however: Split the participant pool in two, e.g., at random. Call them Group A and Group B. Instead of having every strategy play against every other strategy (round-robin), have strategies from Group A play only against all the strategies from Group B. Then, rank participants only within Group A. Do the analogous with Group B. So in the end you obtain two rankings: a ranking of Group A in terms of performance (in terms of utility obtained) against Group B; and a ranking of Group B against Group A.
This approach eliminates the spite incentive entirely. Since you’re not ranked against anyone that you play against, you have no intrinsic interest in your opponent’s utilities.
Further considerations: Of course, there’s a cost to this: if we hold the set of submitted strategies fixed (and thereby ignore the problematic incentives of traditional round-robin), then in some sense the two-groups-tournament is less informative than the single-group round-robin tournament. This is because we evaluate each strategy against a smaller sample of opponent strategies. For instance, if we have 40 participants, then normally we’d get an estimate of each participant’s expected utility based on 39 samples of opponent strategies. With the two-group split, we only get an estimate based on 19 samples (from the same distribution) of opponent strategies. So we get worse at deciding whether the submitted strategies are good/bad. (As the number of submission increases, the downside of halving the number of samples decreases, but the motivating risk of round-robin tournaments is also more pronounced if the number of submissions is small.)
A different possible concern is that outside observers will not abide by the “ranking only within group” rule. If all of the submitted strategies are published, then an observer could simply run a round-robin tournament on the submitted strategies and publish an alternate ranking. This alternate ranking might then confer prestige, and to optimize their position in the alternate ranking, participants are once again incentivized to submit spiteful strategies. To prevent this, one would have to make it difficult enough to reproduce the tournament. (In many cases, one might justifiably hope that nobody will bother publicizing an alternate ranking, though.)
Even if just the overall utility obtained is published, then a third-party observer might simply take the highest-scoring strategy across the two groups to be the “real winner”. For small numbers of participants, the two winners are incomparable, because they faced different sets of opponents. But the distribution over opponents is the same. So as the participant pool grows, the comparison becomes valid. If outside parties naively aggregate across groups and the resulting comparisons confer prestige, participants are once more incentivized to submit spiteful programs to fare better in the aggregated rankings.
To combat this, the tournament organizers could try to publish more limited information about the different strategies’ scores.4
Related ideas: The spite incentive problem and the population split idea follow a common pattern in mechanism design: In many cases, your first idea for a mechanism will set some bad incentives on participants, because of some specific downstream effect of the participants’ decisions. To fix the mechanism, you can remove that downstream effect, usually at some cost.
For instance, this is how you might get from a first- to a second-price auction:
The most natural idea for an auction is to just ask participants (bidders / people interested in the item you’re looking to sell) what they’d be willing to pay for the item and sell to the highest bidder. How much do you then charge the highest bidder? Well, however much they’re willing to pay, of course! Or perhaps, however much they’re willing to pay minus $1 (since otherwise they wouldn’t gain anything from participating).
But now you realize that participants aren’t necessarily incentivized to honestly report how much they’re willing to pay: by reporting a lower number they might get away with paying less for your item.
Let’s say that you want bidders to report their willingness to pay honestly (e.g., because you want to make sure to sell to whoever wants it most). Then to fix the incentive issue, you need to determine the price paid by the winner in a way that doesn’t depend on the winner’s bid, while still making sure that the price is at most equal to the winner’s bid. One way of doing this is to charge them the second-highest bid. (It could also be the third-highest bid or the average of all the other bids, but, of course, these numbers are all lower than the second highest bid and so result in less profit. If in addition to the participants’ bids, you get a signal from a third party, telling you minimum distance between bids is $20, then you could also charge the second bid plus $20.) Of course, the cost is that the price we charge is not informed by the winning participant’s willingness to pay.
The population splitting idea can be discovered by an analogous line of thinking: to fix the spite incentive, you need to remove the influence from your opponent’s utility on your ranking. The simplest way of doing this is to only play against opponents against whom you’re not subsequently ranked.
Of course, the details of the auction case are quite different from the present setting.
The most closely related idea that I’m aware of is about eliminating similar bad incentives in peer review. In peer review, the same people often serve as reviewers and as authors. Conferences often select papers in part based on rankings (rather than just absolute scores) of the papers. In particular, they might choose based on rankings within specific areas. Therefore, if you serve as a reviewer on a paper in your area, you might be incentivized to give the paper a lower score in order to improve the ranking of your paper. The obvious idea to avoid this problem is to make sure that a reviewer isn’t assigned to a paper that they’re competing against. For a brief introduction to this problem and solution, along with some references, see Shah (2022, Section “Dishonest Behavior”, Subsection “Lone Wolf”). I think the fundamental idea here is the same as the idea behind the above partition-based approach to cooperative AI competitions. Some of the details importantly differ, of course. For instance, each reviewer can only review a small number of papers anyway (whereas in the cooperative AI competition one can evaluate each program against all other programs).
Footnotes:
In many cases, the rewards aren’t primarily monetary. Rather, a high ranking is rewarded with attention and prestige, and associated prestige and attention are hard to control at all. But even distributing monetary rewards in proportion to utility is impractical. For example, you now effectively reward people merely for entering the competition at all. Requiring a submission fee to counter this has its own issues (such as presumably becoming subject to gambling regulations). ↩︎
There is some literature on this phenomenon in the context of forecasting competitions. That is, in a forecasting competitions with ranking-based reward, forecasters typically aren’t incentivized to submit predictions honestly, because they want to increase (and sometimes decrease!) the variance of their score. See, e.g., Lichtendahl and Winkler (2007) and Monroe et al. (2025). ↩︎
How big is the spite issue? Well, for one this depends, of course, on the game that is being played. My guess is that in the simple Prisoner’s Dilemma games that most of the existing tournaments have focused on, these spiteful incentives are relatively insignificant. There just aren’t any opportunities to hurt opponents cheaply. But I’d imagine that in more complex games, all kinds of opportunities might come up, and so in particular there might be opportunities for cheap spite.
Second, the importance of spite depends on the number of participants in the tournament. In the extreme case, if there are only two participants, then the interaction between the two is fully zero-sum. As the number of participants grows, the benefits of harming a randomly selected opponent decrease, as a randomly selected opponent is unlikely to be a relevant rival.
The exact dynamics are complicated, however. For instance, if there are only two participants with a realistic chance at first place (perhaps due to technical implementation challenges), then encounters between these top contenders become effectively zero-sum from each player’s perspective – if they can “recognize” each other. ↩︎
A natural first idea is to only publish relative scores for each group. For instance, in each group separately, subtract from each strategy’s utility the utility of the top strategy. This way the published top score in each group will be 0. This will work against a naive third party. But a more sophisticated third party might be able to infer the original scores if there are pairs of very similar strategies between the groups. For instance, in the Iterated Prisoner’s Dilemma, we might imagine that both groups will contain a DefectBot, i.e., a strategy of defecting all the time, regardless of the opponent’s actions. So in some sense this approach obscures too little information. For better protection, one might have to obscure information even more. The question of how to do this is similar to the questions studied in the Differential Privacy framework.
One radical approach would be to only publish the ranking and to never publish numeric scores. Presumably this makes it impossible to compare across groups. This has other downsides, though. If, say, our top-three strategies achieve similar scores, they deserve similar amounts of attention – they are similarly promising approaches to cooperation. If we publish scores, outside observers will be able to tell that this is the case. If we publish just the ranking, observers won’t know whether, say, the second-best strategy is competitive with the best or not. So we’re making it more difficult for outside observers to draw conclusions about the relative promise of different research directions. We might also worry that publishing only the ranking will worsen the incentives toward high-variance strategies, because the reward for coming in at a close second place is lower. ↩︎
The SPI framework tells us that if we choose only between, for instance, aligned delegation and aligned delegation plus surrogate goal, then implementing the surrogate goal is better. This argument in the paper is persuasive pretty much regardless of what kind of beliefs we hold and what notion of rationality we adopt. In particular, it should convince us if we’re expected utility maximizers. However, in general we have more than just these two options (i.e., more than just aligned delegation and aligned delegation plus surrogate goals); we can instruct our delegates in all sorts of ways. The SPI formalism does not directly provide an argument that among all these possible instructions we should implement some instructions that involve surrogate goals. I will call this the surrogate goal justification gap. Can this gap be bridged? If so, what are the necessary and sufficient conditions for bridging the gap?
The problem is related to but distinct from other issues with SPIs (such the SPI selection problem, or the question of why we need safe Pareto improvement as opposed to “safe my-utility improvements”).
Besides describing the problem, I’ll outline four different approaches to bridging the surrogate goal justification gap, some which are at least implicit in prior discussions of surrogate goals and SPIs:
The use of SPIs on the default can be justified by pessimistic beliefs about non-SPIs (i.e., about anything that is not an SPI on the default).
As noted above, we can make a persuasive case for surrogate goals when we face a binary decision between implementing surrogate goals and aligned delegation. Therefore, the use of surrogate goals can be justified if we decompose our overall decision of how to instruct the agents into this binary decision and some set of other decisions, and we then consider these different decision problems separately.
SPIs may be particularly attractive because it is common knowledge that they are (Pareto) improvements. The players may disagree or may have different information about whether any given non-SPI is a (Pareto) improvement or not.
I don’t develop any of these approaches to justification in much detail.
Beware! Some parts of this post are relatively hard to read, in part because it is about questions and ideas that I don’t have a proper framework for, yet.
A brief recap of safe Pareto improvements
I’ll give a brief recap (with some reconceptualization, relative to the original SPI paper) of safe Pareto improvements here. Without any prior reading on the subject, I doubt that this post will be comprehensible (or interesting). Probably the most accessible introductions to the concepts are currently: the introduction of my paper on safe Pareto improvements with Vince Conitzer, and Sections 1 and 2 of Tobias Baumann’s blog post, “Using surrogate goals to deflect threats”.
Imagine that you and Alice play a game G (e.g., a normal-form game) against each other, except that you only play this game indirectly: you both design artificial agents or instruct some human entities that play the game for you. We will call these the agents. (In the SPI paper, these were called the “representatives”.) We will call you and Alice the principals. (In the SPI paper, these were called the “original players”.) We will sometimes consider cases in which the principals self-modify (e.g., change their utility functions), in which case the agents are the same as (or the “successor agents” of) the principals.
We imagine that the agents have great intrinsic competence when it comes to game playing. A natural (default) way to indirectly play G is therefore for you and Alice to both instruct your agents by giving them your utility function (and perhaps any information about the situation that the agents don’t already have), and then telling them to do the best they can. For instance, in the case of human agents, you might set up a simple incentive contract and have your agent be paid in proportion to how much you like the outcome of the interaction.
Now imagine that you and Alice can (jointly or individually) intervene in some way on how the agents play the game, e.g., by giving them alternative utility functions (as in the case of surrogate goals) or by barring them from playing this or that action. Can you and Alice improve on the default?
One reason why this is tricky is that both with and without the intervention, it may be very difficult to assign an expected utility to the interaction between the agents due to equilibrium selection problems. For example, imagine that the base game G is some asymmetric version of the Game of Chicken and imagine that the intervention results in the agents playing some different asymmetric Game of Chicken. In general, it seems very difficult to tell which of the two will (in expectation) result in a better outcome for you (and for Alice).
Roughly, a safe Pareto improvement on the base game G is an intervention on the interaction between the agents (e.g., committing not to take certain action, giving them alternate objectives, etc.) that you can conclude is good for both players, without necessarily resolving hard questions about equilibrium selection. Generally, safe Pareto improvements rest on relatively weak, qualitative assumptions about how the agents play different games.
Here’s an example of how we might conclude something is Pareto-better than the default. Imagine we can intervene to make the agents play a normal-form game G’ instead of G. Now imagine that G’ is isomorphic to G, and that each outcome of G’ is Pareto-better than its corresponding outcome in G. (E.g., you might imagine that G is just the same as G’, except that each outcome has +1 utility for both players. See the aforementioned articles for more interesting examples.) Then it seems plausible that we can conclude that this intervention is good for both players, even if we don’t know how the agents play G or G’. After all, there seems to be no reason to expect that equilibrium selection will be more favorable (to one of the players) in one game relative to the other.
Introducing the problem: the SPI justification gap
I’ll now give a sketch of a problem in justifying the use of SPIs. Imagine (as in the previous “recap” section) that you and Alice play a game against each other via your respective agents. You get to decide what game the agents play. Let’s say you have four options G0,G1,G2,G3 for games that you can let the agents play. Let’s say G0 is some sort of default that G1 is a safe Pareto improvement on G0. Imagine further that there are no other SPI relations between any pair of these games. In particular, G2 and G3 aren’t safe Pareto improvements on G0, and G1 isn’t an SPI on either G2 or G3.
For a concrete example, let’s imagine that G0 is some sort of threat game with aligned delegation (i.e., where the agents have the same objectives as you and Alice, respectively).
Threaten
Not threaten
Give in
0,1 0,1
1,0 1,0
Not give in
-3,-3 -3,-3
1,0 1,0
The black numbers are the agent’s utility functions; the blue numbers are your and Alice’s utility functions. (Since the agents are aligned with you and Alice, the black numbers are the same as the corresponding blue numbers.)
(You might object that, while this game has multiple equilibria, giving in weakly dominates not giving in for the row player and therefore that we should strongly expect this game to result in the (Give in, Threaten) outcome. However, for this post, we have to imagine that the outcome of this game is unclear. One way to achieve ambiguity would be to imagine that (Not give in, Not threaten) is better for the row player than (Give in, Not threaten), e.g., because preparing to transfer the resource takes some effort (even if the resources are never in fact demanded and thus never transferred), or because there’s some chance that third parties will observe whether the row player is resolved to resist threats and are thus likely to threaten the row player in the future).)
Then let’s imagine that G1 is the adoption of a surrogate goal and thus the deflection of any threats to that surrogate goal. Let’s therefore represent G1 as follows:
Threaten surrogate
Not threaten
Give in
0,1 0,1
1,0 1,0
Not give in
-3,-3 1,-3
1,0 1,0
Note that the agent’s utility functions are isomorphic to those in G0. The only difference (highlighted by bold font) is that (Not give in, Threaten surrogate) is better for the principals (you and Alice) than the corresponding outcome (Not give in, Threaten surrogate) in G0.
Let’s say G2 simply consists in telling your agent to not worry so much about threats against you being carried out. Let’s represent this as follows:
Threaten
Not threaten
Give in
0,1 0,1
1,0 1,0
Not give in
-1,-3 -3,-3
1,0 1,0
Finally, let’s say G3 is a trivial game in which you and Alice always receive a payoff of ⅓ each.
Clearly, you should now prefer that your agents play G1 rather than G0. Following the SPI paper, we can offer straightforward (and presumably uncontroversial) justifications of this point. If furthermore you’re sufficiently “anchored” on the default G0, then G1 is your unique best option from what I’ve told you. For example, if you want to ensure low worst-case regret relative to the default you might be compelled to choose G1. (And again, if for some reason you were barred from choosing G2, G3, then you would know that you should choose G1 rather than G0.) The SPI paper mostly assumes this perspective of being anchored on the default.
But now let’s assume that you approach the choice between G0, G1, G2, and G3 from the perspective of expected utility maximization. You just want to choose whichever of the six games is best. Then the above argument shows that G0 should not be played. But it fails to give a positive account of which of the four games you should choose. In particular, it doesn’t make much of a positive case for G1, other than that G1 should be preferred over G0. From an expected utility perspective, the “default” isn’t necessarily meaningful and there is no reason to play an SPI on the default.
In some sense, you might even say that SPIs are self-defeating: They are justified by appeals to a default, but then they themselves show that the default is a bad choice and therefore irrelevant (in the way that strictly dominated actions are irrelevant).
The problem is that we do want a positive account of, say, surrogate goals. That is, we would like to be able to say in some settings that you should adopt a surrogate goal. The point of surrogate goals is not just a negative claim about aligned delegation. Furthermore, in practice whenever we would want to use safe Pareto improvements or surrogate goals, we typically have lots of options, i.e., our situation is more like the G0 versus … versus G3 case than a case of a binary choice (G0 versus G1). That is, in practice we also have lots of other options that stand in no SPI relation to the default (and for which no SPI on the default is an SPI on them). (For example, we don’t face a binary choice between aligned delegation with and without surrogate goal. Within either of these options we have all the usual parameters – “alignment with whom?”, choice of methods, hyperparameters, and so on. We might also have various third options, such as the adoption of different objectives, intervening on the agent’s bargaining strategy, etc.) (Of course, there might also be multiple SPIs on the default. See Section 6 of the SPI paper and the discussion of the SPI selection problem in the “related issues” section below.)
For the purpose of this post, I’ll refer to this as the SPI justification gap. In the example of surrogate goals, the justification gap is the gap between the following propositions:
A) We should prefer the implementation of surrogate goals over aligned delegation.
B) We should implement surrogate goals.
The SPI framework justifies A very well (under various assumptions), including from an expected utility maximization perspective. In many settings, one would think B is true. But unless we are willing to adopt a “default-relative” decision making framework (like minimizing worst-case regret relative to the default), B doesn’t follow from A and the SPI framework doesn’t justify B. So we don’t actually have a compelling formal argument for adopting surrogate goals and in particular we don’t know what assumptions (if any) are needed for surrogate goals to be fully compelling (assuming that surrogate goals are compelling at all).
Now, one immediate objection might be: Why do we even care about whether an SPI is chosen? If there’s something even better than an SPI (in expectation), isn’t that great? And shouldn’t we be on the lookout for interventions on the agents’ interaction that are even better than SPIs? The problem with openness to non-SPIs is basically the problem of equilibrium selection. If we narrow our decision down to SPIs, then we only have to choose between SPIs. This problem might be well-behaved in various ways. For instance, in some settings, the SPI is unique. In other settings even the best-for-Alice SPI (among SPIs that cannot be further safely Pareto-improved upon) might be very good for you. Cf. Section 6 on “SPI selection problem section” in the original SPI paper. Meanwhile, if we don’t narrow our interventions on G down to SPIs on G, then in many cases the choice between interventions on G is effectively just choosing a strategy for G, which may be difficult. In particular, it may be that if we consider all interventions on G, then we also need to consider interventions that we only very slightly benefit from. For example, in the case of games with risks of conflict (like the Demand Game in the original SPI paper), all SPIs that cannot be further safely improved upon eliminate conflict outcomes (and don’t worsen the interaction in other ways). Whereas, non-safe Pareto improvements (i.e., an intervention that is good for both players in expectation relative to some probabilistic beliefs about game play) may also entail a higher probability of conceding more (in exchange for a decreased risk of conflict).
Below, I will first relate the justification gap problem to some other issues in the SPI framework. I will then discuss a few approaches to addressing the SPI justification gap. Generally, I think compelling, practical arguments can be made to bridge the SPI justification gap. But it would be great if more work could be done to provide more rigorous arguments and conditions under which these arguments do and don’t apply.
I should note that in many real-world cases, decisions are not made by expected utility maximization (or anything very close to it) anyway. So, even if the justification gap cannot be bridged at all, SPIs could remain relevant in many cases. For instance, in many cases interventions have to be approved unanimously (or at least approximately unanimously) by multiple parties with different values and different views about equilibrium selection. If no intervention is approved, then the default game is played. In such cases, SPIs (or approximate SPIs) on the default may be the only interventions that have a good chance at universal approval. For instance, an international body might be most likely to adopt laws that are beneficial to everyone while not changing the strategic dynamics much (say, rules pertaining to the humane treatment of prisoners of war). (In comparison, they might be less likely to adopt improvements that change the strategic dynamics – say, bans of nuclear weapons – because there will likely be someone who is worried that they might be harmed by such a law.) Another real-world example is that of “grandfathering in” past policies. For instance, imagine that an employer changes some of its policies for paying travel expenses (e.g., from reimbursing item by item to paying a daily allowance in order to decrease administrative costs). Then the employer might worry that some of its employees will prefer the old policy. In practice, the employer may wish to not upset anyone and thus seek a Pareto improvement. In principle, it could try to negotiate with existing employees to find some arrangement that leaves them happy while still enabling the implementation of the new policy. (For instance, it could raise pay to compensate for the less favorable reimbursement policy.) But in many contexts, it may be easier to simply allow existing employees to stay on the old policy (“grandfathering in” the old policy), thus guaranteeing to some extent that every employee’s situation will improve.
Some related issues
For clarification, I’ll now discuss a few other issues and clarify how they relate to the SPI justification gap, as discussed in this post.
First, the SPI justification gap is part of a more general question: “Why SPIs/surrogate goals?” As described above, earlier work gives, in my view, a satisfactory answer to a different aspect of the “Why SPIs?” question. Specifically, SPIs are persuasive in case of binary comparison: if we have a choice between two options G and G’ and G’ is an SPI on G, then we have good enough reason to choose G’ over G. This post is specifically about an issue that arises when we move beyond binary comparisons. (More generally, it’s about issues that arise if we move beyond settings where one of the available options is an SPI on all the other available options.)
Second, the justification gap is a separate problem from the SPI selection problem (as discussed in Section 6 of the SPI paper). The SPI justification gap arises even if there is just one SPI (as in the above G0,….,G3 example). Conversely, if we can in some way bridge the SPI justification gap (i.e., if we can justify restricting attention to interventions that are SPIs), then the SPI selection problem remains. The problems also seem structurally different. The justification gap isn’t intrinsically about reaching multiplayer agreement in the way that SPI selection is. That said, some of the below touches on SPI selection (and equilibrium selection) here and there. Conversely, we might expect that approaches to SPI selection would also relate to SPI justification. For instance, some criteria for choosing between SPIs could also serve as criteria that favor SPIs over non-SPIs. For example, maximizing minimum utility improvement both induces (partial) preferences over SPIs and preferences for SPIs over non-SPIs.
Second, the safe Pareto improvement framework assumes that when deciding whether to replace the default with something else, we restrict attention to games that are better for both players. (This is a bit similar to imposing a “voluntary participation” or “individual rationality” constraint in mechanism design.) In the context of surrogate goals this is motivated by worries of retaliation against aggressive commitments. From the perspective of an expected utility maximizer, it’s unclear where this constraint comes from. Why not propose some G that is guaranteed to be better for you, but not guaranteed to be better for the other player than the default? This is a different question than the question we ask in this post. Put concisely, this post is about justifying the “safe” part, not about justifying the “Pareto” part. (At least in principle, we could consider “safe my-utility improvements” (which are explicitly allowed to be bad for the opponent relative to the default) and ask when we are justified in specifically pursuing these over other interventions. I’m here considering safe Pareto improvements throughout, because the concept of safe Pareto improvement is more widely known and discussed.) Nevertheless, I think the problem of justifying the Pareto constraint – the constraint that the other player is (“safely” or otherwise) not made worse off than the default – is similar and closely related to the SPI justification gap. Both are about a “safety” or “conservativeness” constraint that isn’t straightforwardly justifiable on expected-utility grounds. See also “Solution idea 3” below, which gives a justification of safety that is closely related to the Pareto requirement (and justifications thereof).
Solution idea 1: Pessimistic beliefs about one’s ability to choose non-SPIs
Consider again the choice between G0,….,G3, where G1 is an SPI on G0 and there are no other SPI relations. Probably the most straightforward justification for SPIs would be a set of beliefs under which the expected utility of G0 is higher than the expected utility of any of the games G2 and G3. Specifically, you could have a belief like the following, where G0 is the default: If I can’t prove from some specific set of assumptions (such as “isomorphic games are played isomorphically”, see the SPI paper) that u(G) > u(G0), then I should believe E[u(G)] < E[u(G0)]. (I might hold this either as a high-level belief or it might be that all my object-level beliefs satisfy this.) Of course, in some sense, this is just a belief version of decision principles like minimizing regret relative to the default. Michael Dennis et al. make this connection explicit in the appendix of “Emergent Complexity and Zero-shot Transfer via Unsupervised Environment Design” as well as some ongoing unpublished work on self-referential claims.
Intuitively, non-SPI pessimism is based on trust in the abilities of the agents that we’re delegating to. For instance, in the case of threats and surrogate goals, I might be pessimistic about telling my agent that the opponent is likely bluffing, because I might expect that my agent will have more accurate beliefs than me about whether the opponent is bluffing. (On the other hand, if I can tell my agent that my opponent is bluffing in a way that is observable to the opponent, then such announcements are a sort of credible commitment. And if I can commit in this way and my agent cannot commit, then it might very well be that I should commit, even if doing so in some sense interferes with my agent’s competence.) One might be pessimistic about G2 for similar reasons.
I don’t think such pessimistic beliefs are plausible in general, however. One argument against “non-SPI pessimism” is that one can give “almost SPIs”, about which I would be optimistic, and about which we need to be optimistic if we wish to apply SPIs in the real world (where exact SPIs are hard to construct). For example, take the Demand Game example from the SPI paper and decrease Player 1’s payoffs of the outcome (DL,RL) by 0.00001. You can’t make a clean SPI argument anymore, but I’d still in practice be happy with the approach proposed by the SPI paper. Or take the above example (the choice between G0, G1, G2, G3), imagine that as a better version of G3 you can also choose a guaranteed payoff of 0.99. If you want the Pareto part, you may imagine that Alice also receives 0.99 in this case. Rejecting this option seems to imply great optimism about G0. (You need to believe that Alice’s agent will play Not Threaten with probability >99%.) Such optimism seems uncompelling. (We could construct alternative games G0 in which such optimism seems even less compelling.) Maybe the example is even more powerful if we take a third party’s perspective that wants to improve both players’ utility (and imagine again that a certain payoff of 0.99 for both players is available). After all, if G0 is better than 0.99 for one player, 0.99 is much better than G0 for the other player.
Solution idea 2: Decision factorization
(I suspect this section is harder to read than the others. There seem to be more complications to these ideas than those in the other sections. I believe the approach in this section to be the most important, however.)
One intuitive justification for the application SPIs is that the decision of whether to use the SPI/surrogate goal can be made separately from other decisions. This is quite explicit in the original surrogate story: Commit to the surrogate goal now – you can still think about, say, whether you should commit to not give in later on. If right now you only decide whether to use a surrogate goal or not, then right now you face a binary decision where one option is an SPI on the other, which is conceptually unproblematic. If instead, you decide between all possible ways of instructing your agents at once, you have lots of options and the SPI concept induces only a partial order on these options. In some cases a decision may be exogenously factorized appropriately, e.g., you might be forced to only decide whether to use surrogate goals on day 1, and to make other decisions on day 2 (or even have someone else make other decisions on day 2). The challenge is that in most real-world cases, decisions aren’t externally factorized.
Here’s a toy model, inspired by surrogate goals. Let’s say that you play a game in which you choose two bits, so overall you have four actions. However, imagine that you choose the two bits in sequence. Perhaps when thinking about the first bit, you don’t yet know what second bit you will choose. Let’s say that each sequence of bits in turn gives rise to some sort of game – call these games G00, G01, G10, and G11, where the first bit encodes the first choice and the second encodes the second. Intuitively you might imagine that the first choice is the choice of whether to (immediately) adopt a surrogate goal, and the second choice is whether to make some commitment to resist unfair outcomes. Importantly, you need to imagine that if you adopt the surrogate goal, then your choice on the second day will be made on the basis of your new utility function, the one that includes the surrogate goal. Anyway, you don’t need to have such a specific picture in mind.
Now, let’s say that you find that G10 is an SPI on G00 and that G11 is an SPI on G01. Imagine further that the choice of the second bit is isomorphic between the case where the first bit chosen was 1 and the case where the second bit chosen was 0, that is: in G1 (the state of affairs where the first bit was chosen to be 1 and the second bit is not yet chosen) you will choose 0 if and only if you choose 0 in G0. Then overall, you can conclude that G1 is an SPI on G0. Since in the first time step you only choose between 0 and 1, you can conclude by SPI logic from the above that you should choose 1 at the first time step. (Of course, the decision in G1 will still be difficult.)
Here’s a non-temporal informal example of how factorization might work. Imagine that AliceCorp is building an AI system. One of the divisions of AliceCorp is tasked with designing the bargaining behavior of the AI system (e.g., by training the AI system on some set of bargaining scenarios). A different “SPI division” is tasked with assessing whether to modify the system’s utility function (e.g., by modifying the training rewards) to include surrogate goals. This SPI division is explicitly not supposed to induce a utility function that causes the system to give in less – influencing the bargaining policy is the job of the bargaining division after all. Importantly, the bargaining division either doesn’t know about the possibility of surrogate goals or doesn’t care about it. (For example, imagine that the bargaining division is paid in proportion to how well the AI system ends up handling bargaining situations in the real world. Then it is important that if a surrogate goal is implemented, the bargaining division receives low incentive pay if a surrogate threat is carried out.) If AliceCorp happens to be set up in this way, then – ignoring SPI selection, loads of implementation details, etc. – the SPI division faces a binary choice between implementing the SPI and not implementing the SPI.
Again, the main idea here is that we factorize our decision into multiple decisions and then we consider these decisions separately. In particular, the decision of whether to adopt the SPI or not becomes an easy binary decision.
Note that the factorization argument requires some structure on the set of possible games that might be played. The structure is what allows you to make the decision about the SPI in isolation, without considering your other choices. (For instance, adopting a surrogate goal doesn’t stop you from committing to never give in later on.) The argument doesn’t work if you just choose between four arbitrary games (as in the G0 versus … G3 case), one of which is an SPI on one of the other ones.
Also, note that depending on the details of the settings, the separation of the different decisions seems to be necessary to make the story compelling. For example, in the surrogate goal story, it’s important to first adopt surrogate goals and only then decide whether to make other commitments. If you, say, self-modify all at once to have a surrogate goal and to never give in, then the opponent should treat this as if you had just committed to never give in without the surrogate goal. There are other cases in which the order does not matter. For example, imagine that you choose 0 versus 1 and also choose between A, B, and C. Then you play some game whose payoffs are determined in some complex way by the A/B/C choice. Additionally, the first number (0 vs. 1) is simply added to each payoff in the resulting game. Choosing 1 is an SPI over choosing 0, and there’s no particular problem with choosing 0 versus 1 and A versus B versus C at the same time. (And there’s also no need, it would seem, to have separate “departments” make the two different choices.) So in this case it doesn’t matter whether the factorization is somehow (e.g., temporarily) (self-)imposed on the decision maker. It still matters that the factorization exists, though. For instance, if choosing the first number to be 1 precludes choosing the letter A, then we can’t necessarily make a case for choosing 1 over 0 anymore.
In a recent draft, DiGiovanni et al. (2024) provide a justification of safe Pareto improvements from an expected utility maximization standpoint. (See also their less technical blog post: “Individually incentivized safe Pareto improvements in open-source bargaining”.) I think, and Anthony DiGiovanni tentatively agrees, that one of its underlying ideas can be viewed as factorizing the choice set (which in their setting is the set of computer programs). In particular, their Assumptions 5 and 9 each enable us to separate out the choice of “renegotiation function” (their mechanism for implementing SPIs) from other decisions (e.g., how hawkish to be), so that we can reach conclusions of the form, “whatever we choose for the ‘other stuff’, it is better to use a renegotiation function” (see their Proposition 2 and Theorem 3). Importantly their results don’t require the factorization to manifest in, say, the temporal order of decisions. So in that way it’s most similar to the example at the end of the preceding paragraph. They also allow the choice of the “other stuff” to depend on the presence of negotiation, which is different from all examples discussed in this post. Anyway, there’s a lot more to their paper than this factorization and I myself still have more work to do to get a better understanding of it. Therefore, a detailed discussion of this paper is beyond the scope of this post, and the discussion in this section is mostly naive to the ideas in their paper.
I like the factorization approach. I think this is how I usually think of surrogate goals working in practice. But I nonetheless have many questions about how well this justification works. Generally, the story assumes many aspects about the agent’s reasoning as given and I’d be interested in whether these assumptions could be taken to be variable. Here are some specific concerns.
1) In some cases, the story assumes that decisions are factorized and/or faced in some fixed specific order that is provided exogenously. Presumably, the SPI argument doesn’t work in all orders. For example, in the “two-bits story” let’s say you first have to choose {11,00} versus {10,01} and then choose within the respective set (as opposed to first choosing {10,11} versus {00,01} and then within the chosen set). Then neither of the two decisions individually can be resolved by an SPI argument. What if the agent can choose herself in what order to think about the different decisions?
There are lots of ideas to consider here. For example, maybe agents should first consider all possible ordered factorizations of their decision and then use a factorization that allows for an SPI. But this all seems non-trivial to work out and justify. For instance, in order to avoid infinite regress, many possible lines of meta-reasoning have to be suppressed. But then we need a justification for why this particular form of meta-reasoning (how can I decompose my decision problems in the best possible way?) should not be suppressed. Also, how do we arrive at the judgment that the SPI-admitting factorization is best? It seems that this to some extent presupposes some kind of pro-SPI judgment.
2) Relatedly, the argument hinges to some extent on the assumption that there is some point in time at which the opportunity to implement the SPI expires (while relevant other decisions – the ones influenced by the SPI – might still be left to be made later). For example, in the two-bit story, the SPI can only be implemented on the first day, and an important decision is made on the second day. In some real-world settings this might be realistic.* But in some cases, it might be unrealistic. That is, in some cases the decision of whether to adopt the SPI can be delayed for as long as we want.
As an example, consider the following variant of the two-bits story. First, imagine that in order for choosing the first bit to be 1 to be an SPI over choosing it to be 0, we do need to choose the bits sequentially. For instance, imagine that the first bit determines whether the agent implements a surrogate goal and the second bit determines whether the agent commits to be a more aggressive bargainer. Now imagine that the agent has 100 time steps. (Let’s assume that the setting doesn’t have any “commitment race”-type dynamics – there’s no benefit to commit to an aggressive strategy early in order to make it so that the opponent sees your commitment before they make a commitment. E.g., you might imagine that a report of your commitments is only sent to opponents after all 100 time steps have passed.) In each time step, the agent gets to think a little. It can then make some commitment about the two bits. For example, it might commit to not choose 11, or commit to choose 1 as the first bit. Intuitively, we want the agent to at some point choose the first bit, and then choose the second bit in the last step. Perhaps in this simple toy model you might specifically want the agent to choose the first bit immediately, but in most practical settings, figuring out whether a surrogate goal could be used and figuring out how to best apply it takes some time. In fact, one would think that in practice there’s almost always some further thinking that could be done to improve the surrogate goal implementation. If there’s SPI selection, then you might want to wait to decide what SPI to go for. This would suggest that the agent would push the surrogate goal implementation back to the 99th time step. (Because sequential implementation is required, you cannot push implementation back to the 100th time step – on the 100th time step, you need to choose whether to commit to an aggressive bargaining policy while already having adopted the surrogate goal.)
The problem is that if you leave the SPI decision to the final time step, this leaves very little time for making the second decision (the decision of whether to adopt an aggressive bargaining policy). (You might object: “Can’t the agent think about the two decisions in parallel?” But one big problem with this is that before adopting a surrogate goal (before setting the first bit to be 1), the agent has different goals than it has after adopting the surrogate goal. So, if the agent anticipates the successful implementation of surrogate goals, it has little interest in figuring out whether future threats would be credible. In general, the agent would want to think thoughts that make its future self less likely to give in. (No, this doesn’t violate the law of total probability.))
One perspective on the above is that even once you (meta-)decided to first decide whether or how to implement the surrogate goal, you still face a ternary choice at each point: A) commit to the surrogate goal; B) commit against the use of the surrogate goal; and C) wait and decide A versus B later. The SPI framework tells you that A > B. But it can’t compare A and C.
Solution idea 3: Justification from uncertainty about one another’s beliefs
Here’s a third idea. Contrary to the other two approaches, this one hinges much more on the multi-agent aspect of SPIs. Roughly, this justification for playing SPIs on the default is as follows: Let’s say it’s common knowledge that the default way of playing is good (relative to a randomly selected intervention, for instance). Also, if G’ is an SPI on G, then by virtue of following from a simple set of (chosen-to-be-)uncontroversial assumptions, it is common knowledge that G’ is better than G. So, everyone agrees that G’ would be better for everyone than G, and everyone knows that everyone else agrees that G’ would be better for everyone than G, and so on. In contrast, if G’ is not an SPI on G and your belief that G’ is better than G is based on forming beliefs about how the agents play G (which might have many equilibria), then you don’t know for sure whether the other players would agree with this judgment or not. This is an obstacle to the use of “unsafe Pareto improvements” for a number of reasons, which I will sketch below. Compare the Myerson–Satterthwaite theorem, which suggests that Pareto-improving deals often fail to be made when the parties have access to private information about whether any given deal is Pareto-improving. Relative to this theorem, the following points are pre-theoretical.
First and most straightforwardly, if you (as one of the principals) know that G’ is better for both you and Alice than G, but you don’t know whether Alice (the other principal) knows that G’ is better (for her) than G, then – in contexts where Alice has some sort of say – you will worry that Alice will oppose G’. If there’s a restriction on the number of times that you can propose an intervention, this is an argument against proposing G’ from an expected utility maximization perspective.
Here’s an extremely simple numeric example. Let’s say you get to propose one intervention and Alice has to accept or reject. If she rejects, then G is played. (Note that we thereby already avoid part of the justification problem – the default G is, to some extent, imposed externally in a way that it normally would not be.) Now let’s say that G’ is an SPI on G. Let’s say that you also think that some other G’’ is better in expectation for you than G, but you think there’s a 20% chance that Alice will disagree that G’’ is better than G. Then for you to propose G’’ rather than G’, it would need to be the case that 80% * (u(G’’) – u(G)) > u(G’) – u(G’’). (This assumes that you don’t take Alice’s judgment as evidence about how good G’’ is for you.) Thus, even if the SPI G’ is slightly worse for you than the non-SPI G’’, you might propose the SPI G’, because it is more likely to be accepted.
As an extension of the above, you might worry that the other player will worry that any proposed non-SPI was selected adversarially. That is, if you propose playing G’ instead of G to Alice and G’ is not an SPI on G, then Alice might worry that you only proposed G’ because it disproportionately favors you at her cost. That is, Alice might worry that you have private information about the agents and that this information tells you that G’ is specifically good for you in a way that might be bad for her.
Here’s again a toy example. Let’s imagine again that G is in fact played by default (which, again, assumes part of the justification gap away). Imagine that there is exactly one SPI on G. Let’s say that additionally there are 1000 other possible games G1,…,G1000 to play that all look like they’re slightly better in expectation for both players than G. Finally, imagine that you receive private information that implies that one of the 1000 games is very good for you and very bad for the other player. Now let’s say that you’ve specifically observed that G233 is the game that is great for you and bad for your opponent. If you now propose that you and the opponent play G233, your opponent can’t tell that you’re trying to trick them. Conversely, if you propose G816, then your opponent doesn’t know that you’re not trying to trick them. With some caveats, standard game-theoretic reasoning would therefore suggest that if you propose any of G1,…,G1000, you ought to propose G233. Knowing this, the other principal will reject the proposal. Thus, you know that proposing any of G1,…,G1000 will result in playing G. If instead you propose the SPI on G, then the other principal has no room for suspicion and no reason to reject. Therefore, you should propose G.
There are many complications to this story. For example, in the above scenario, the principals could determine at random which of the Gi to play. So if they have access to some trusted third party who can randomize for them, they could generate l at random and then choose to play Gi. (They could also use cryptography to “flip a coin by telephone” if they don’t have access to a trusted third party.) But then what if the games in G1,…,G1000 aren’t Pareto improvements on average, and instead the agents also have private information about which of these games are (unsafe) Pareto improvements? There are lots of questions to explore here, too many to discuss in this post.
As a third consideration, agents might worry that in the process of settling on a non-SPI, they reveal private information, and that revealing private information might have downsides. For example, if the default G is a Game of Chicken, then indicating willingness to “settle” for some fixed amount reveals a (lower bound on the) belief in the opposing agent’s hawkishness. It’s bad for you to reveal yourself to believe in the opponent’s hawkishness.
Again, there are lots of possible complications, of course. For instance, zero-knowledge mechanisms could be used to bargain in a way that requires less information to be exchanged.
Solution idea 4: Safe Pareto improvements as Schelling points
To end on a simpler idea: Safe Pareto improvements may be Schelling points (a.k.a. focal points) in some settings. For instance, you might imagine a setting in which the above justifications don’t quite apply. Then SPIs might stand out by virtue of standing out in slight alterations of the setting in which the above justifications do apply.
It seems relatively hard to say anything about the Schelling points justification of safe Pareto improvements, because it’s hard to justify preferences for Schelling points in general. For instance, imagine you and Bob have to both pick a number between 1 and 10 and you both get a reward if you both pick the same number. Perhaps you should pick 1 (or 10) because it’s the smallest (resp. largest) number. If you know each other to be Christians, perhaps you should pick 3. Perhaps you should pick 7, because 7 is the most common favorite number. If you just watched a documentary about Chinese culture together, perhaps you should pick 8, because 8 is a lucky number in China. And so on. I doubt that there is a principled answer as to which of these arguments matters most. Similarly I suspect that in complex settings (in which similarly many Schelling point arguments can be made), it’s unclear whether SPIs are more “focal” than non-SPIs.
Acknowledgments
Discussions with Jesse Clifton, Anthony DiGiovanni and Scott Garrabrant and inspired parts of the contents of this post. I also thank Tobias Baumann, Vincent Conitzer, Emery Cooper, Michael Dennis, Alexander Kastner and Vojta Kovarik for comments on this post.
* Arguing for this is beyond the scope of this post, but just to give a sense: Imagine that AliceCorp builds an AI system. AliceCorp has 1000 programmers and getting the AI to do anything generally requires a large effort by people across the company. Now I think AliceCorp can make lots of credible announcements about what AliceCorp is and isn’t doing. For example, some of the programmers might leak information to the public if AliceCorp were to lie about how it operates. However, once AliceCorp has a powerful AI system, it might lose the ability to make some forms of credible commitments. For example, it might be that AliceCorp can now perform tasks by having a single programmer work in collaboration with AliceCorp’s AI system. Since it’s much easier to find a single programmer who can be trusted not to leak (and presumably the AI system can be made not to leak information), it’s now much easier for AliceCorp to covertly implement projects that go against AliceCorp’s public announcements.
In earlier work, I claimed that (in the specific context of ECL) if you are trying to benefit someone’s moral view as part of some cooperative arrangement, only the consequentialist aspects of their moral values are relevant to you. That is, if you want to act cooperatively toward Alice’s moral values, then you need to consider only the consequentialist components of Alice’s value system. For instance, you need to ask yourself: Would Alice wish for there to be fewer lies? You don’t need to ask yourself whether Alice considers it a moral imperative not to lie herself (except insofar as it relates to the former question).
While I still believe that there’s some truth to this claim, I now believe that the claim is straightforwardly incorrect. In short, it seems plausible that, for example, Alice’s moral imperative not to lie extends to actions by others that Alice brings about via trade. (Furthermore, it seems plausible that this is the case even if Alice doesn’t consider it a moral imperative to, for example, donate money to fund fact checkers in a distant country. That is, it seems plausible that this is the case even if Alice doesn’t care about lies in a fully consequentialist way.) I’ll give further intuition pumps for the relevance of deontological constraints below. I’ll take a more abstract perspective in the section right after giving the examples.
Related work.Toby Ord’s article on moral trade also has a section (titled “Consequentialism, deontology, and virtue ethics”) that discusses how the concept of moral trade interacts with the distinction between deontological and consequentialist ethics. (He also discusses virtue ethics, which I ignore to keep it simple.) However, he doesn’t go into much detail and seems to make different points than this post. For instance, he argues that even deontologists are often somewhat consequentialist (which my earlier writing also emphasizes). He also makes at least one point that is somewhat contrary to the claims in this article. I will discuss this briefly below (under example P1).
Examples. I’ll now give some examples of situations in which it seems intuitively compelling that someone’s deontological duties propagate through a trade relationship (P1–3). I’ll vary both the duties and the mode of trade. I’ll then also provide two negative examples (N1,2), i.e., examples where deontological norms arguably don’t propagate through trade. The examples are somewhat redundant. There’s no need to read them all!
The examples will generally consider the perspective of the deontologist’s trading partner who is uncertain about the deontologist’s views (rather than the deontologist herself). I’m taking the deontologist’s trading partner’s perspective because I’m interested in how to deal with other’s deontological views in trade. I’ll assume that one cannot simply ask the deontologist, because this would shift all difficulty to the deontologist and away from the deontologist’s trading partner.
P1: Say you have a friend Alice. Alice follows the following policy: Whenever someone does something that’s good for her moral views, Alice pays them back in some way, e.g., monetarily. For instance, Alice is concerned about animal welfare. Whenever she learns that hardcore carnivore Bob eats a vegetarian meal, she sends him a dollar. (There are lots of practical game-theoretic difficulties with this – can vegetarians all earn free money from Alice by claiming that they are vegetarian only to be nice to her? – but let’s ignore these.)
Now, let’s say that Carol is considering what actions to take in light of Alice’s policy. Carol comes up with the following idea. Perhaps she should put up posters falsely claiming that local cows graze from heavily polluted pastures. Let’s say that she is sure that this has a positive impact on animal welfare (i.e., that she has reason to not be concerned about backlash, etc.). But now let’s say that Alice once said that she wouldn’t want to lie even when doing so has positive consequences. Meanwhile, she also isn’t a “truth maximizer”; she argued that the cause of correcting others’ inconsequential lies out in the world isn’t worthwhile. Should Carol expect to receive payment?
To me it seems plausible that Carol shouldn’t or at least she should be doubtful about whether she will be paid. (For what it’s worth, it seems that Claude 3 agrees.) Given Alice’s stance on lying, Alice surely wouldn’t want to put up the posters herself. It seems plausible to me that Alice then also wouldn’t want to pay Carol to put up such posters (even if the payment is made in retrospect).
Here’s one way to think about it. Imagine that Alice has written a book, “What I’m happy to pay people to do”. The book contains a list with items such as “raise awareness of animal welfare conditions under factory farming”, “eating less meat”, etc. Would we expect the book to contain an item, “put up misleading posters that cause people to avoid meat”? Again, I would imagine that the answer is no. Putting such an item in the book is directly causing others to lie on Alice’s behalf. More specifically, it’s causing others to lie in pursuit of Alice’s goals. This doesn’t seem so different from Alice lying herself. Perhaps when Carol tries to benefit Alice’s moral views, she should act on what Carol would predict Alice to have put in the book (even if Alice never actually writes such a book).
Interestingly, Toby Ord’s article on the subject contains a hint in the opposite direction: “[I]t is possible that side constraints or agent-relative value could encourage moral trade. For example, someone might think that it is impermissible for them to lie in order to avoid some suffering but that it wouldn’t be impermissible to convince someone else to make this lie in order to avoid the suffering.”
P2: Let’s say Alice and Bob are decision-theoretically similar enough that they would cooperate with each other in a one-shot Prisoner’s Dilemma (even under somewhat asymmetric payoffs). Let’s say that Alice could benefit Bob but have to lie in order to do so. Conversely, let’s say that Bob could benefit Alice, but would have to steal in order to do so. Alice believes that one (deontologically) ought not to steal, but thinks that lying is in principle acceptable in and of itself. Conversely, Bob believes that one (deontologically) ought not to lie, but thinks that stealing is acceptable.
Ignoring the deontological constraints, Alice would benefit Bob to make it more likely that Bob benefits Alice. But now what if they take the deontological constraints into account? Would Alice still benefit Bob to make it more likely that Bob benefits Alice? Again, I think it’s plausible that she wouldn’t. By lying in order to benefit Bob, Alice makes it likely that Bob would steal. In some sense Alice makes Bob steal in service of Alice’s goals. It seems intuitive that Alice’s deontological constraints against stealing should still apply. It would be a strange “hack” if deontological constraints didn’t apply in this context; one could circumvent deontological constraints simply by trading one’s violations with others. (It’s a bit similar to the plot of “Strangers on a Train”, in which a similar swap is proposed to avoid criminal liability.) (Again, compare Toby Ord’s comment, as discussed in P1.)
P3: The previous examples illustrate the propagation of negative duties (duties of the “you shalt not…” variety). I’ll here give an example of how positive duties might also transfer.
The country of Charlesia is attacked by its neighbor. Charlesia is a flourishing liberal democracy, so Alice considers it an ethical imperative to protect Charlesia. In order to do so, Alice hires a group of mercenaries to fight on Charlesia’s side. Since time is of the essence, the mercenaries aren’t given a proper contract that specifies their exact objectives, rules of engagement and such.
Two weeks later, the mercenaries find themselves marching through the warzone in Charlesia. They encounter a weak old man who is asking to be evacuated. Doing so would distract significant resources from the mercenaries’ military mission. The mercenaries and their equipment are very expensive. So, clearly, if Alice wanted to spend money in order to help weak old people, she wouldn’t have spent the money on hiring the mercenaries. Thus, if Alice is a pure consequentialist, she wouldn’t want the mercenaries to help the weak old man. So if the mercenaries wanted to act in mercenary fashion (i.e., if they wanted to do whatever Alice wants them to do), should they leave the weak old man to die?
Not necessarily! I think it is entirely plausible that Alice would want the mercenaries to act according to common-sense, not fully consequentialist ethics. That is, it seems plausible that Alice would want the mercenaries to observe the moral obligation to help the old man, as Alice would presumably do if she was in the mercenaries’ place. As in the other cases, it seems intuitive that the mercenaries are in some sense acting on Alice’s behalf. So it seems that Alice would want the mercenaries to act somewhat similar to how she would act.
N1: Let’s say Alice from P1 wants to pay Bob to eat more vegetarian meals. Unfortunately, Bob’s social group believes that “real men eat meat”. Therefore, Bob says that if he becomes a vegetarian (or reducetarian), he’ll have to lie to his friends about his diet. (If this lie is not consequential enough to be ethically relevant, you can add further context. For instance, you might imagine that Bob’s lies will cause his friends to develop less accurate views about the healthiness of different diets.) Let’s say that Alice observes deontological norms of honesty. Does this mean that Bob should reason that becoming a vegetarian wouldn’t be a successful cooperative move towards Alice?
It’s unclear, but in this case it seems quite plausible that Bob can benefit Alice by becoming a closet vegetarian. It seems that the lie is more of a side effect – Bob doesn’t lie for Alice, he lies for himself (or in some sense for his social group). So it seems that (according to conventional ethical views) Alice doesn’t bear much of a responsibility for the lie. So in this case, it seems plausible to me that Alice’s deontological constraint against lying isn’t (strongly) propagated through the trade relationship between Alice and Bob.
N2: The inhabitants of a sparsely populated swampland want to found a state. (Founding a state can be viewed as a many-player trade.) Founding a state would require agreement from Alice – she’s the only accountant in the swampland and the envisioned state would require her to keep an eye on finances. (That said, lots of other inhabitants of the swampland are also individually necessary for the state, and only a small fraction of the state’s tax revenue would come from Alice.) Unfortunately, Alice can’t be present for the founding meeting of the state. Thus, in designing the state, the remaining inhabitants of the swampland have to make guesses about Alice’s interests.
After some discussion, over 90% of the resources of the state have been allocated, all to issues that Alice is known to be on board with: infrastructure, a medical system, social security, educatio, etc. The state policies also include a few measures that Alice agrees with and that only a minority of other inhabitants of the swampland care about, including a museum, a concert hall and a public library.
One of the last issues to be sorted out is law enforcement and in particular the legal system. In the past, vigilante justice has ruled the land. Now a formal set of laws are to be enforced by a police. Everyone (including Alice) agrees that this will reduce crime, will make punishments more humane, and will make it less likely that innocents are unfairly punished. Most inhabitants of the swampland agree that there should be a death penalty for the most severe crimes. However, Alice holds that all killing is unethical. In the past, when she carried out vigilante justice herself, she strictly avoided killings, even when doing so meant letting someone get away with murder.
If the members of the founding meeting propose a state policy that involves the death penalty, must they expect that Alice will refuse to perform accounting for the state?
Again, I think that under many circumstances it’s reasonable for the others to expect that Alice will not block the state. It seems that if people like Alice, then founding states (or other large social arrangements) with Alice would simply be too difficult. Perhaps hermits would reject the state, but agents who function in societies can’t be so fussy.
Conceptualization via a model of deontology. I’ll here propose a simple model of deontological ethics to get a better grasp on the role of deontological norms in trade. I won’t immediately use this model for anything, so feel free to skip this section!
Consider the following model of deontological values. Let’s say your actions can result in consequences via different types of “impact paths”. Consequentialists don’t care about the impact path – they just care about the consequence itself. Deontologists generally care about the consequences, but also care about the impact path and depending on the type of the impact path, they might care more or less about the consequence. For instance, if an outcome is brought about via inaction, then a deontologist might care less about it. Similarly, impact paths that consist of long causal chains that are hard to predict might matter less to deontologists. Meanwhile, deontologists care a lot about the “empty” impact path, i.e., about cases where the action itself is the consequence. For example, deontologists typically want to minimize lies that they tell themselves much more than they care about not acting in a way that causes others to lie. Which impact paths matter how much is up to the individual deontological view and different deontologists might disagree. (I’m not sure how good of a model of deontological values this is. It’s certainly a very consequentialist perspective. (Cf. Sinnott-Armstrong (2009) [paywalled].) It’s also quite vague, of course.)
In this model of deontological views, trade is simply one type of impact path by which we can bring about outcomes. And then the different types of trades like tit for tat, signing contracts, ECL, and other forms of acausal trade are specific subtypes of impact paths. Different deontologists have different views about the paths. So in particular, there can be deontological views according to which bringing something about by trade is like bringing it about by inaction. But I think it’s more natural for deontologists to care quite a bit about at least some simple impact paths via trade, as argued above.
If impact paths via trade matter according to Alice’s deontological views, then Alice’s trading partners need to take Alice’s deontologist views into account (unless they simply receive explicit instructions from Alice about what Alice wants them to do).
Implications for ECL. (For this section, I assume familiarity with ECL (formerly MSR). Please skip this section if you’re unfamiliar with this.)
Do deontological views matter for how we should do ECL? In principle, it clearly does matter. For instance, consequentialists who otherwise don’t abide by deontological norms (even for instrumental reasons) should abide by deontological norms in their implementation of ECL.
That said, I think in practice there are lots of reasons why following deontological views via ECL might not matter so much, especially because even absent the above consideration ECLers might already take deontological norms into account: (Perhaps this is also a reason why neither I nor anyone else to my knowledge pointed out that my earlier writing on ECL was wrong to claim that deontological views of trading partners can be ignored.)
Consequentialists typically argue that consequentialism itself already implies that we should follow deontological norms in practice. For instance, consequentialists might say that in practice lies (especially consequential lies) are eventually found out with high enough probability that the risk of being found out typically outweighs the potential benefits of getting away with the lie. It is also sometimes argued that to apply consequentialism in practice, one has to follow simple rules (since assessing all the different possible consequences of an action is intractable) and that the rules proposed by deontologists are rules that consequentialists should follow in lieu of trying to calculate the consequences of all of their actions. If you agree with these sorts of views, then in particular you’d hold that consequentialist ECLers should already abide by deontological norms anyway, even if they only consider the consequentialist aspects of the ethical views they’re trying to benefit. Of course, there might be deontological norms that aren’t justifiable on consequentialist grounds. The propagation of these norms through trade would be relatively important.
My sense is that pure consequentialists are rare. My sense is that most EAs are, if anything, more likely than others to abide by standard ethical norms (such as not lying). (Sam Bankman-Fried is commonly brought up as an example of an overly consequentialist EA.) In any case, if you yourself already subscribe to lots of deontological norms, then importing deontological norms via ECL makes less of a difference. Again, you might of course specifically not subscribe to some specific popular deontological norms. If so, then ECL makes these norms more relevant to you.
Even without deontological views in the picture, ECL often pushes toward more deontological-norm-abiding behavior. For instance, ECL suggests a less adversarial posture towards people with other value systems.
Some research questions. I should start by saying that I assume there’s already some literature on the relation between deontological views and trade in the ethics literature. In traditional trade contexts (e.g., paying the baker so that she bakes us bread), this seems like a pertinent issue. For instance, I assume deontologists have considered ethical consumerism. I haven’t tried to review this literature. I would imagine that it mostly addresses the normative ethical dimension, rather than, say, the game-theoretic aspects of it. There’s also a question to what extent the moral trade context is fundamentally different from the traditional economic trade context.
An immediate obstacle to researching the role of deontological views in moral trade is that we don’t have toy models of deontological ethics. For trading on consequentialist grounds, we have some good economic toy models (agents investing in different types of interventions with comparative advantages, see, for example, the ECL paper). Are there corresponding toy models to get a better grasp on trading when deontological constraints are involved? Perhaps the simplest formal model would be that deontologists only agree to a trade if agreeing to the deal doesn’t increase the total number of times that their norms are violated, but that’s arguably too strong.
In real-world trades, one important question is to what extent and how a trading partner’s deontological constraints propagate beyond actions taken specifically to benefit that trading partner. The positive examples above (P1–3) consider cases where agent 1 faces a single choice solely to benefit agent 2 and then ask whether agent 2’s deontological views restrict that choice. Meanwhile, the negative examples above (N1,2) involve more complicated interactions between multiple decision problems and between the interests of multiple actors. So, in general what happens if agent 1 also faces other decisions in which she pursues exclusively her own goals – do the deontological views apply to those actions as well in some way (as in N1)? What should happen in multi-party trade (as in N2)? Let’s say agent 1 makes choices in order to benefit both agent 2 and agent 3, and that only agent 2 has deontological ethics. Then do agent 2’s deontological views fully apply to agent 1’s actions? Or is it perhaps sufficient for agent 2’s participation in the trade to not increase the number of violations by agent 1 of agent 2’s duties? (If so, then what is the right counterfactual for what trade(s) happen?) Of course, these are in part (descriptive) ethical questions. (“How do deontologists want their deontological views to propagate through trade?”) I wonder whether a technical analysis can nonetheless provide some insights.
Acknowledgments. I thank Emery Cooper and Joseph Carlsmith for helpful comments and discussions.
The pragmatist maxim of action relevance: You should only ask yourself questions that are (in principle) decision-relevant. That is, you should only ask yourself a question Q if there is some (hypothetical) decision situation where you take different actions depending on how you answer Q.
I am aware that this is quite vague and has potential loopholes. (For any question Q, does it count as a decision situation if someone just asks you what you think about Q? We have to rule this out somehow if we don’t want the maxim to be vacuous.) For the purpose of this post, a fairly vague notion of the maxim will suffice.
The action relevance maxim rules out plenty of definitional questions. E.g., it recommends against most debates on the question, “If a tree falls in a forest and no one is around to hear it, does it really make a sound?”. (It does allow asking the question, “What meaning should we give to the word ‘sound’?”) Importantly, it allows asking normative ethical questions such as, “should we kill murderers or put them in jail?”. By allowing hypothetical scenarios, you can still ask questions about time travel and so forth. Perhaps it has some controversial implications for when and why one should discuss consciousness. (If you already fully understand how, say, a biological system works, then how will it matter for your actions whether that system is conscious? I can only think of ethical implications – if a system is conscious, I don’t want to harm it. Therefore, consciousness becomes primarily a question of what systems we should care about. This seems similar to some eliminativist views, e.g., that of Brian Tomasik.) That said, for every definitional question (what is “sound”, “consciousness”, etc.), there are pragmatically acceptable questions, such as, “What is a rigorous/detailed definition of ‘consciousness’ that agrees with (i.e., correctly predicts) our intuitions about whether a system is conscious?”.) I think the implications for anthropics / self-locating beliefs are also controversial. Anyway, I find the above pragmatist maxim compelling.
It is worth noting that there are also other pragmatist principles under which none of the below applies. For example, Eliezer Yudkowsky has a post titled “Making Beliefs Pay Rent in Anticipated Experiences”. Self-locating beliefs anticipate experiences. So even without action relevance they “pay rent” in this sense.
Successful pragmatist critiques of anthropics
I think some pragmatist critiques of anthropics are valid. Here’s the most important critique that I think is valid: (It uses some terms that I’ll define below.)
If you have non-indexical preferences andyou think updateless decision theory – i.e., maximizing ex ante expected utility (expected utility from the perspective of the prior probability distribution) – is the only relevant normative decision criterion, then the philosophical question of what probabilities you should assign in scenarios of imperfect recall disappears.
First, some explanations and caveats: (I’ll revisit the first two later in this post.)
By non-indexical preferences I mean preferences that don’t depend on where in the scenario you are. For example, in Sleeping Beauty, an indexical preference might be: “I prefer to watch a movie tonight.” This is indexical because the meaning of “tonight” differs between the Monday and Tuesday instantiations of Beauty. The Tuesday instantiation will want Beauty to watch a movie on Tuesday night, while the Monday instantiation will not care whether Beauty watches a movie on Tuesday night.
I’ll leave it to another post to explain what I consider to be a “philosophical” question. (Very roughly, I mean: questions for which there’s no agreed-upon methodology for evaluating proposed answers and arguments.) I’ll give some questions below about self-locating beliefs that I consider to be non-philosophical, such as how to compute optimal policies.
Of course, scenarios of imperfect recall may also involve other (philosophical) issues that aren’t addressed by UDT (the maxim of following the ex ante optimal policy) and that don’t arise in, say, Sleeping Beauty or the absent-minded driver. For example, we still have to choose a prior, deal with problems of game theory (such as equilibrium selection), deal with infinities (e.g., as per infinite ethics) and so on. I’m not claiming that UDT addresses any of these problems.
As an example, optimizing ex ante utility is sufficient to decide whether to accept or reject any given bet in Sleeping Beauty. Also, one doesn’t need to answer the question, “what is the probability that it is Monday and the coin came up Heads?” (On other questions it is a bit unclear whether the ex ante perspective commits to an answer or not. In some sense, UDTers are halfers: in variants of Sleeping Beauty with bets, the UDTers expected utility calculations will have ½ in place of probabilities and the calculation overall looks very similar to someone who uses EDT and (double) halfing (a.k.a. minimum-reference-class SSA). On the other hand, in Sleeping Beauty without bets, UDTers don’t give any answer to any question about what the probabilities are. On the third hand, probabilities are closely tied to decision making anyway. So even (“normal”, non-UDT) halfers might say that when they talk about probabilities in Sleeping Beauty, all they’re talking about is what numbers they’re going to multiply utilities with when offered (hypothetical) bets. Anyway: Pragmatism! There is no point in debating whether UDTers are halfers or not.)
Some other, less central critiques succeed as well. In general, it’s common to imagine purely definitional disputes arising about any philosophical topic. So, if you show me a (hypothetical) paper titled, “Are SIA probabilities really probabilities?”, I will be a little skeptical of the paper’s value.
(There are also lots of other possible critiques of various pieces of work on anthropics that are outside the scope of this post. Arguably too many papers rely too much on intuition pumps. For instance, Bostrom’s PhD thesis/book on anthropics is sometimes criticized for this (anonymous et al., personal communication, n.d.). I also think that anthropic arguments applied to the real world (the Doomsday argument, the simulation argument, arguments from fine tuning, etc.) often don’t specify that they use specific theories of self-locating beliefs.)
The defense
I now want to defend some of the work on anthropics against pragmatist critiques. The above successful critique already highlights, to some extent, three caveats. Each of these gives rise to a reason why someone might think about how to reason de se (from “within” the scenario, “updatefully”) about games of imperfect recall:
Indexical preferences. Ex ante optimization (UDT) alone doesn’t tell you what to do if you have indexical preferences, because it’s not clear how to aggregate preferences between the different “observer moments”. Armstrong (2011) shows a correspondence between methods of assigning self-locating beliefs (SIA, etc.) and methods of aggregating preferences across copies (average and total utilitarianism). That’s a great insight! But it doesn’t tell you what to do. (Perhaps it’s an argument for relativism/antirealism: you can choose whatever way of aggregating preferences across observer moments you like, and so you could also choose whatever method of assigning self-locating beliefs that you like. But even if you buy into this relativist/antirealist position, you still need to decide what to do.)
Rejecting updatelessness (e.g., claiming it’s irrational to pay in counterfactual mugging). If the ex ante optimal/updateless choice is not the unambiguously correct one, then you have to ask yourself what other methods of decision making you find more compelling.
Asking non-philosophical questions of what procedures work. One might want to know which kinds of reasoning “work” for various notions of “work” (satisfying the reflection principle; when used for decision making: avoiding synchronic or diachronic Dutch books, being compatible with the ex ante optimal/updatelessness policy). Why?
I’m sure some philosophers do this just out of curiosity. (“Non-minimum reference class SSA seems appealing. I wonder what happens if we use it to make decisions.” (It mostly doesn’t work.))
But there are also lots of very practical reasons that apply even if we fully buy into updatelessness. In practice, even those who buy fully into updatelessness talk about updating their probabilities on evidence in relatively normal ways, thus implicitly assigning the kind of self-locating beliefs that UDT avoids. (For example, they might say, “I read a study that caused me to increase my credence in vitamin D supplements being beneficial even in the summer. Therefore, I’ve ordered some vitamin D tablets.” Not: “From my prior’s perspective, the policy of ordering vitamin D tablets upon reading such and such studies is greater than the policy of not taking vitamin D tablets when exposed to such studies.”) Updating one’s beliefs normally seems more practical. But if in the end we care about ex ante utility (UDT), then does updating even make sense? What kind of probabilities are useful in pursuit of the ex ante optimal/updateless policy? And how should we use such probabilities?
As work in this area shows: both SIA probabilities (thirding) and minimum-reference class SSA probabilities (double halfing) can be useful, while non-minimum-reference class SSA probabilities (single halfing) probably aren’t. Of the two that work, I think SIA actually more closely matches intuitive updating. (In sufficiently large universes, every experience occurs at least once. Minimum-reference class SSA therefore makes practically no updates between large universes.) But then SIA probabilities need to be used with CDT! We need to be careful not to use SIA probabilities with EDT.
Relatedly, some people (incl. me) think about this because they wonder how to build artificial agents that choose correctly in such problems. Finding the ex ante optimal policy directly is generally computationally difficult. Finding CDT+SIA policies is likely theoretically easier than finding an ex ante optimal policy (CLS-complete as opposed to NP-hard), and also can be done using practicable modern ML techniques (gradient descent). Of course, in pursuit of the ex ante optimal policy we need not restrict ourselves to methods that correspond to methods involving self-locating beliefs. There are some reasons to believe that these methods are computationally natural, however. For example, CDT+SIA is roughly computationally equivalent to finding local minima of the ex ante expected utility function.
Acknowledgments
I thank Emery Cooper, Vince Conitzer and Vojta Kovarik for helpful comments.
[I assume the reader is familiar with Newcomb’s problem and causal decision theory. Some familiarity with basic theoretical computer science ideas also helps.]
The Adversarial Offer
In a recently (Open-Access-)published paper, I (together with my PhD advisor, Vince Conitzer) proposed the following Newcomb-like scenario as an argument against causal decision theory:
> Adversarial Offer: Two boxes, B1 and B2, are on offer. A (risk-neutral) buyer may purchase one or none of the boxes but not both. Each of the two boxes costs $1. Yesterday, the seller put $3 in each box that she predicted the buyer would not acquire. Both the seller and the buyer believe the seller’s prediction to be accurate with probability 0.75.
If the buyer buys one of the boxes, then the seller makes a profit in expectation of $1 – 0.25 * $3 = $0.25. Nonetheless, causal decision theory recommends buying a box. This is because at least one of the two boxes must contain $3, so that the average box contains at least $1.50. It follows that the causal decision theorist must assign an expected causal utility of at least $1.50 to (at least) one of the boxes. Since $1.50 exceeds the cost of $1, causal decision theory recommends buying one of the boxes. This seems undesirable. So we should reject causal decision theory.
The randomization response
One of the obvious responses to the Adversarial Offer is that the agent might randomize. In the paper, we discuss this topic at length in Section IV.1 and in the subsection on ratificationism in Section IV.4. If you haven’t thought much about randomization in Newcomb-like problems before, it probably makes sense to first check out the paper and only then continue reading here, since the paper makes more straightforward points.
The information-theoretic variant
I now give a new variant of the Adversarial Offer, which deals with the randomization objection in a novel and very interesting way. Specifically, the unique feature of this variant is that CDT correctly assesses randomizing to be a bad idea. Unfortunately, it is quite a bit more complicated than the Adversarial Offer from the paper.
Imagine that the buyer is some computer program that has access to a true random number generator (TRNG). Imagine also that the buyer’s source code plus all its data (memories) has a size of, say, 1GB and that the seller knows that it has (at most) this size. If the buyer wants to buy a box, then she will have to pay $1 as usual, but instead of submitting a single choice between buying box 1 and buying box 2, she has to submit 1TB worth of choices. That is, she has to submit a sequence of 2^43 (=8796093022208) bits, each encoding a choice between the boxes.
If the buyer buys and thus submits some such string of bits w, the seller will do the following. First, the seller determines whether there exists any deterministic 1GB program that outputs w. (This is undecidable. We can fix this if the seller knows the buyer’s computational constraints. For example, if the seller knows that the buyer can do less than 1 exaFLOP worth of computation, then the seller could instead determine only whether there is a 1GB program that produces w with at most 1 exaFLOP worth of computation. This is decidable (albeit not very tractable).) If there is no such program, then the seller knows that the buyer randomized. The buyer then receives no box while the seller keeps the $1 payment. The buyer is told in advance that this is what the seller will do. Note that for this step, the seller doesn’t use her knowledge of the buyer’s source code other than its length (and its computational constraints).
If there is at least one 1GB program that outputs w deterministically, then the seller forgets w again. She then picks an index i of w at random. She predicts w[i] based on what she knows about the buyer and based on w[1…i-1], i.e., on all the bits of w preceding i. Call the prediction w’[i]. She fills the box based on her prediction w’[i] and the buyer receives (in return for the $1) the box specified by w[i].
Why the information-theoretic variant is interesting
The scenario is interesting because of the following three facts (which I will later argue to hold):
The seller makes a profit off agents who try to buy boxes, regardless of whether they do so using randomization or not.
CDT and related theories (such as ratificationism) assess randomizing to be worse than not buying any box.
CDT will recommend buying a box (mostly deterministically).
I’m not aware of any other scenarios with these properties. Specifically, the novelty is item 2. (Our paper offers a scenario that has the other two properties.) The complications of this scenario – letting the agent submit a TB worth of choices to then determine whether they are random – are all introduced to achieve item 2 (while preserving the other items).
In the following, I want to argue in more detail for these three points and for the claim that the scenario can be set up at all (which I will do under claim 1).
1. For this part, we need to show two things:
A) Intuitively, if the agent submits a string of bits that uses substantially more than 1GB worth of randomness, then he is extremely likely to receive no box at all.
B) Intuitively, if the agent uses only about 1GB or less worth randomness, then the seller – using the buyer’s source code will likely be able to predict w[i] with high accuracy based on w[1…i-1].
I don’t want to argue too rigorously for either of these, but below I’ll give intuitions and some sketches of the information-theoretic arguments that one would need to give to make them more rigorous.
A) The very simple point here is that if you create, say, a 2GB bitstring w where each bit is determined by a fair coin flip, then it is very unlikely that there exists a program that deterministically outputs w. After all, there are many more ways to fill 2GB of bits than there are 1GB programs (about 2^(2^33) as many). From this one may be tempted to conclude that if the agent determines, say, 2GB of the TB of choices by flipping coin, he is likely to receive no box. But this argument is incomplete, because there are other ways to use coin flips. For example, the buyer might use the following policy: Flip 2GB worth of coins. If they all come up heads, always take box B. Otherwise follow some given deterministic procedure.
To make the argument rigorous, I think we need to state the claim information-theoretically. But even this is a bit tricky. For example, it is not a problem per se for w to have high entropy if most of the entropy comes from a small part of the distribution. (For example, if with probability 0.01 the seller randomizes all choices, and with the remaining probability always chooses Box 1, then the entropy of w is 0.01*1TB = 10GB (??), but the buyer is still likely to receive a box.) So I think we’d need to make a more complicated claim, of the sort: if there is no substantial part (say, >p) of the distribution over w that has less than, say, 2GB of entropy, then with high probability (>1-p), the agent will receive no box.
B) Again, we can make a simple but incomplete argument: If of the 1TB of choices, only, say, 2GB are determined by random coin flips, then a randomly sampled bit is likely to be predictable from the agent’s source code. But again, the problem is that the random coin flips can be used in other ways. For example, the buyer might use a deterministic procedure to determine w (say, w=01010101…), but then randomly generate a number n (with any number n chosen with probability 2^-n, for instance), then randomly sample n indices j of w and flip w[j] for each of them. This may have relatively low entropy. But now the seller cannot perfectly predict w[i] given w[1…i-1] for any i.
Again, I think a rigorous argument requires information theory. In particular, we can use the fact that H(w) = H(w[0])+H(w[1]|w[0])+H(w[2]|w[0,1])+…, where H denotes entropy. If H(w) is less than, say, 2GB, then the average of H(w[i]|w[1…i-1]) must be at most 2GB/1TB = 1/500. From this, it follows immediately that with high probability, w[i] can be predicted with high accuracy given w[1…i-1].
2. This is essential, but straightforward: Generating w at random causes the seller to determine that w is determined at random. Therefore, CDT (accurately) assesses randomly generating w to have an expected utility near $-1.
3. Finally, I want to argue that CDT will recommend buying a box. For this, we only need to argue that CDT prefers some method of submitting w over not submitting a box. So consider the following procedure: First, assign beliefs over the seller’s prediction w’[0] of the first bit. Since there are only two possible boxes, for at least one of the boxes j, it is the case that P(w’[0]=j)<=½, where P refers to the probability assigned by the buyer. Let w[0] = j. We now repeat this inductively. That is, for each i given the w[1…i-1] that we have already constructed, the buyer sets w[i]=k s.t. P(w’[i]=k||w[1…i-1])<=½.
What’s the causal expected utility of submitting w thus constructed? Well, for one, because the procedure is deterministic (if ties are broken deterministically), the buyer can expect that she will receive a box at all. Now, for all i, the buyer thinks that if i is sampled by the seller for the purpose of determining which box to give to the buyer, then the buyer will in causal expectation receive $1.50, because the seller will predict the wrong box, i.e. w’[i] ≠ w[i], with probability at least ½.
(This post assumes that the reader is fairly familiar with the decision theory of Newcomb-like problems. Schwarz makes many of the same points in his post “On Functional Decision Theory” (though I disagree with him on other things, such as whether to one-box or two-box in Newcomb’s problem). Similar points have also been made many times about the concept of updatelessness in particular, e.g., see Section 7.3.3 of Arif Ahmed’s book “Evidence, Decision and Causality”, my post on updatelessness from a long time ago, or Sylvester Kollin’s “Understanding updatelessness in the context of EDT and CDT”. Preston Greene, on the other hand, argues explicitly for a view opposite of the one in this post in his paper “Success-First Decision Theories”. ETA: Similar points have also been made w.r.t. the “Why ain’cha rich?” argument, which is an argument for EDT (and other one-boxing theories) and against CDT based on Newcomb’s problem. See, for example, Bales (2018) and Wells (2019) (thanks to Sylvester Kollin and Miles Kodama, respectively, for pointing out these papers).)
I sometimes read the claim that one decision theory “outperforms” some other decision theory (in general or in a particular problem). For example, Yudkowsky and Soares (2017) write: “FDT agents attain high utility in a host of decision problems that have historically proven challenging to CDT and EDT: FDT outperforms CDT in Newcomb’s problem; EDT in the smoking lesion problem; and both in Parfit’s hitchhiker problem.” Others use some variations of this framing (“dominance”, “winning”, etc.), some of which I find less dubious because they have less formal connotations.
Based on typical usage, these words make it seem as though there was some agreed upon or objective metric to compare decision theories in any particular problem and that MIRI is claiming to have found a theory that is better according to that metric (in some given problems). This would be similar to how one might say that one machine learning algorithm outperforms another on the CIFAR dataset, where everyone agrees that ML algorithms are better if they correctly classify a higher percentage of the images, require less computation time, fewer samples during training, etc.
However, there is no agreed-upon metric to compare decision theories, no way to asses even for a particular problem whether one decision theory (or its recommendation) does better than another. (This is why the CDT-versus-EDT-versus-other debate is at least partly a philosophical one.) In fact, it seems plausible that finding such a metric is “decision theory-complete” (to butcher another term with a specific meaning in computer science). By that I mean that settling on a metric is probably just as hard as settling on a decision theory and that mapping between plausible metrics and plausible decision theories is fairly easy.
For illustration, consider Newcomb’s problem and a few different metrics. One possible metric is what one might call the causal metric, which is the expected payoff if we were to replace the agent’s action with action X by some intervention from the outside. Then, for example, in Newcomb’s problem, two-boxing “performs” better than one-boxing and CDT “outperforms” FDT. I expect that many causal decision theorists would view something of this ilk as the right metric and that CDT’s recommendations are optimal according to the causal metric in a broad class of decision problems.
A second possible metric is the evidential one: given that I observe that the agent uses decision theory X (or takes action Y) in some given situation, how big of a payoff do I expect the agent to receive. This metric directly favors EDT in Newcomb’s problem, the smoking lesion, and again a broad class of decision problems.
A third possibility is a modification of the causal metric. Rather than replacing the agent’s decision, we replace its entire decision algorithm before the predictor looks at and creates a model of the agent. Despite being causal, this modification favors decision theories that recommend one-boxing in Newcomb’s problem. In general, the theory that seems to maximize this metric is some kind of updateless CDT (cf. Fisher’s disposition-based decision theory).
One could also use the notion of regret (as discussed in the literature on multi-armed bandit problems) as a performance measure, which probably leads to ratificationism.
Lastly, I want to bring up what might be the most commonly used class of metrics: intuitions of individual people. Of course, since intuitions vary between different people, intuition provides no agreed upon metric. It does, however, provide a non-vacuous (albeit in itself weak) justification for decision theories. Whereas it seems unhelpful to defend CDT on the basis that it outperforms other decision theories according to the causal metric but is outperformed by EDT according to the evidential metric, it is interesting to consider which of, say, EDT’s and CDT’s recommendations seem intuitively correct.
Given that finding the right metric for decision theory is similar to the problem of decision theory itself, it seems odd to use words like “outperforms” which suggest the existence or assumption of a metric.
I’ll end with a few disclaimers and clarifications. First, I don’t want to discourage looking into metrics and desiderata for decision theories. I think it’s unlikely that this approach to discussing decision theory can resolve disagreements between the different camps, but that’s true for all approaches to discussing decision theory that I know of. (An interesting formal desideratum that doesn’t trivially relate to decision theories is discussed in my blog post Decision Theory and the Irrelevance of Impossible Outcomes. At its core, it’s not really about “performance measures”, though.)
Second, I don’t claim that the main conceptual point of this post is new to, say, Nate Soares or Eliezer Yudkowsky. In fact, they have written similar things, see, for instance, Ch. 13 of Yudkowsky’s Timeless Decision Theory, in which he argues that decision theories are untestable because counterfactuals are untestable. Even in the aforementioned paper, claims about outperforming are occasionally qualified. E.g., Yudkowsky and Soares (2017, sect. 10) say that they “do not yet know […] (on a formal level) what optimality consists in”.) Unfortunately, most outperformance claims remain unqualified. The metric is never specified formally or discussed much. The short verbal descriptions that are given make it hard to understand how their metric differs from the metrics corresponding to updateless CDT or updateless EDT.
So, my complaint is not so much about these authors’ views but about a Motte and Bailey-type inconsistency, in which the takeaways from reading the paper superficially are much stronger than the takeaways from reading the whole paper in-depth and paying attention to all the details and qualifications. I’m worried that the paper gives many casual readers the wrong impression. For example, gullible non-experts might get the impression that decision theory is like ML in that it is about finding algorithms that perform as well as possible according to some agreed-upon benchmarks. Uncharitable, sophisticated skim-readers may view MIRI’s positions as naive or confused about the nature of decision theory.
In my view, the lack of an agreed-upon performance measure is an important fact about the nature of decision theory research. Nonetheless, I think that, e.g., MIRI is doing and has done very valuable work on decision theory. More generally I suspect that being wrong or imprecise about this issue (that is, about the lack of performance metrics in the decision theory of Newcomb-like problems) is probably not an obstacle to having good object-level ideas. (Similarly, while I’m not a moral realist, I think being a moral realist is not necessarily an obstacle to saying interesting things about morality.)
Acknowledgement
This post is largely inspired by conversations with Johannes Treutlein. I also thank Emery Cooper for helpful comments.
[I assume that the reader is familiar with Newcomb’s problem and the Prisoner’s Dilemma against a similar opponent and ideally the equilibrium selection problem in game theory.]
Its defining characteristic is the following: The Pareto-dominant outcome (i.e., the outcome that is best for both players) (S,S) is Nash equilibrium. However, (H,H) is also a Nash equilibrium. Moreover, if you’re sufficiently unsure what your opponent is going to do, then H is the best response. If two agents learn to play this game and they start out playing the game at random, then they are more likely to converge to (H,H). Overall, we would like it if the two agents played (S,S), but I don’t think we can assume this to happen by default.
Now what if you played the trust dilemma against a similar opponent (specifically one that is similar w.r.t. how they play games like the trust dilemma)? Clearly, if you play against an exact copy, then by the reasoning behind cooperating in the Prisoner’s Dilemma against a copy, you should play S. More generally, it seems that a similarity between you and your opponent should push towards trusting that if you play S, the opponent will also play S. The more similar you and your opponent are, the more you might reason that the decision is mostly between (S,S) and (H,H) and the less relevant are (S,H) and (H,S).
What if you played against an opponent who knows you very well and who has time to predict how you will choose in the trust dilemma? Clearly, if you play against an opponent who can perfectly predict you (e.g., because you are an AI system and they have a copy of your source code source code), then by the reasoning behind one-boxing in Newcomb’s problem, you should play S. More generally, the more you trust your opponent’s ability to predict what you do, the more you should trust that if you play S, the opponent will also play S.
Here’s what I find intriguing about these scenarios. In these scenarios, one-boxers might systematically arrive at a different (more favorable) conclusion than two-boxers. However, this conclusion is still compatible with two-boxing, or with blindly applying Nash equilibrium. In the trust dilemma, one-boxing type reasoning merely affects how we resolve the equilibrium selection problem, which the orthodox theories generally leave open. This is in contrast to the traditional examples (Prisoner’s Dilemma, Newcomb’s problem) in which the two ways of reasoning are in conflict. So there is room for implications of one-boxing, even in an exclusively Nash equilibrium-based picture of strategic interactions.
“Abstract”: Some have claimed that moral realism – roughly, the claim that moral claims can be true or false – would, if true, have implications for AI alignment research, such that moral realists might approach AI alignment differently than moral anti-realists. In this post, I briefly discuss different versions of moral realism based on what they imply about AI. I then go on to argue that pursuing moral-realism-inspired AI alignment would bypass philosophical and help resolve non-philosophical disagreements related to moral realism. Hence, even from a non-realist perspective, it is desirable that moral realists (and others who understand the relevant realist perspectives well enough) pursue moral-realism-inspired AI alignment research.
Different forms of moral realism and their implications for AI alignment
Roughly, moral realism is the view that “moral claims do purport to report facts and are true if they get the facts right.” So for instance, most moral realists would hold the statement “one shouldn’t torture babies” to be true. Importantly, this moral claim is different from a claim about baby torturing being instrumentally bad given some other goal (a.k.a. a “hypothetical imperative”) such as “if one doesn’t want to land in jail, one shouldn’t torture babies.” It is uncontroversial that such claims can be true or false. Moral claims, as I understand them in this post, are also different from descriptive claims about some people’s moral views, such as “most Croatians are against babies being tortured” or “I am against babies being tortured and will act accordingly”. More generally, the versions of moral realism discussed here claim that moral truth is in some sense mind-independent. It’s not so obvious what it means for a moral claim to be true or false, so there are many different versions of moral realism. I won’t go into more detail here, though we will revisit differences between different versions of moral realism later. For a general introduction on moral realism and meta-ethics, see, e.g., the SEP article on moral realism.
I should note right here that I myself find at least “strong versions” of moral realism implausible. But in this post, I don’t want to argue about meta-ethics. Instead, I would like to discuss an implication of some versions of moral realism. I will later say more about why I am interested in the implications of a view I believe to be misguided, but for now suffice it to say that “moral realism” is a majority view among professional philosophers (though I don’t know how popular the versions of moral realism studied in this post are), which makes it interesting to explore the view’s possible implications.
The implication that I am interested in here is that moral realism helps with AI alignment in some way. One very strong version of the idea is that the orthogonality thesis is false: if there is a moral truth, agents (e.g., AIs) that are able to reason successfully about a lot of non-moral things will automatically be able to reason correctly about morality as well and will then do what they infer to be morally correct. On p. 176 of “The Most Good You Can Do”, Peter Singer defends such a view: “If there is any validity in the argument presented in chapter 8, that beings with highly developed capacities for reasoning are better able to take an impartial ethical stance, then there is some reason to believe that, even without any special effort on our part, superintelligent beings, whether biological or mechanical, will do the most good they possibly can.” In the articles “My Childhood Death Spiral”, “A Prodigy of Refutation” and “The Sheer Folly of Callow Youth” (among others), Eliezer Yudkowsky says that he used to hold such a view.
Of course, current AI techniques do not seem to automatically include moral reasoning. For instance, if you develop an automated theorem prover to reason about mathematics, it will not be able to derive “moral theorems”. Similarly, if you use the Sarsa algorithm to train some agent with some given reward function, that agent will adapt its behavior in a way that increases its cumulative reward regardless of whether doing so conflicts with some ethical imperative. The moral realist would thus have to argue that in order to get to AGI or superintelligence or some other milestone, we will necessarily have to develop new and very different reasoning algorithms and that these algorithms will necessarily incorporate ethical reasoning. Peter Singer doesn’t state this explicitly. However, he makes a similar argument about human evolution on p. 86f. in ch. 8:
The possibility that our capacity to reason can play a critical role in a decision to live ethically offers a solution to the perplexing problem that effective altruism would otherwise pose for evolutionary theory. There is no difficulty in explaining why evolution would select for a capacity to reason: that capacity enables us to solve a variety of problems, for example, to find food or suitable partners for reproduction or other forms of cooperative activity, to avoid predators, and to outwit our enemies. If our capacity to reason also enables us to see that the good of others is, from a more universal perspective, as important as our own good, then we have an explanation for why effective altruists act in accordance with such principles. Like our ability to do higher mathematics, this use of reason to recognize fundamental moral truths would be a by-product of another trait or ability that was selected for because it enhanced our reproductive fitness—something that in evolutionary theory is known as a spandrel.
A slightly weaker variant of this strong convergence moral realism is the following: Not all superintelligent beings would be able to identify or follow moral truths. However, if we add some feature that is not directly normative, then superintelligent beings would automatically identify the moral truth. For example, David Pearce appears to claim that “the pain-pleasure axis discloses the world’s inbuilt metric of (dis)value” and that therefore any superintelligent being that can feel pain and pleasure will automatically become a utilitarian. At the same time, that moral realist could believe that a non-conscious AI would not necessarily become a utilitarian. So, this slightly weaker variant of strong convergence moral realism would be consistent with the orthogonality thesis.
I find all of these strong convergence moral realisms very implausible. Especially given how current techniques in AI work – how value-neutral they are – the claim that algorithms for AGI will all automatically incorporate the same moral sense seems extraordinary and I have seen little evidence for it1 (though I should note that I have read only bits and pieces of the moral realism literature).2
It even seems easy to come up with semi-rigorous arguments against strong convergence moral realism. Roughly, it seems that we can use a moral AI to build an immoral AI. Here is a simple example of such an argument. Imagine we had an AI system that (given its computational constraints) always chooses the most moral action. Now, it seems that we could construct an immoral AI system using the following algorithm: Use the moral AI to decide which action of the immoral AI system it would prevent from being taken if it could only choose one action to be prevented. Then take that action. There is a gap in this argument: perhaps the moral AI simply refuses to choose the moral actions in “prevention” decision problems, reasoning that it might currently be used to power an immoral AI. (If exploiting a moral AI was the only way to build other AIs, then this might be the rational thing to do as there might be more exploitation attempts than real prevention scenarios.) Still (without having thought about it too much), it seems likely to me that a more elaborate version of such an argument could succeed.
Here’s a weaker moral realist convergence claim about AI alignment: There’s moral truth and we can program AIs to care about the moral truth. Perhaps it suffices to merely “tell them” to refer to the moral truth when deciding what to do. Or perhaps we would have to equip them with a dedicated “sense” for identifying moral truths. This version of moral realism again does not claim that the orthogonality thesis is wrong, i.e. that sufficiently effective AI systems will automatically behave ethically without us giving them any kind of moral guidance. It merely states that in addition to the straightforward approach of programming an AI to adopt some value system (such as utilitarianism), we could also program the AI to hold the correct moral system. Since pointing at something that exists in the world is often easier than describing that thing, it might be thought that this alternative approach to value loading is easier than the more direct one.
I haven’t found anyone who defends this view (I haven’t looked much), but non-realist Brian Tomasik gives this version of moral realism as a reason to discuss moral realism:
Moral realism is a fun philosophical topic that inevitably generates heated debates. But does it matter for practical purposes? […] One case where moral realism seems problematic is regarding superintelligence. Sometimes it’s argued that advanced artificial intelligence, in light of its superior cognitive faculties, will have a better understanding of moral truth than we do. As a result, if it’s programmed to care about moral truth, the future will go well. If one rejects the idea of moral truth, this quixotic assumption is nonsense and could lead to dangerous outcomes if taken for granted.
(Below, I will argue that there might be no reason to be afraid of moral realists. However, my argument will, like Brian’s, also imply that moral realism is worth debating in the context of AI.)
As an example, consider a moral realist view according to which moral truth is similar to mathematical truth: there are some axioms of morality which are true (for reasons I, as a non-realist, do not understand or agree with) and together these axioms imply some moral theory X. This moral realist view suggests an approach to AI alignment: program the AI to abide by these axioms (in the same way as we can have automated theorem provers assume some set of mathematical axioms to be true). It seems clear that something along these lines could work. However, this approach’s reliance on moral realism is also much weaker.
As a second example, divine command theory states that moral truth is determined by God’s will (again, I don’t see why this should be true and how it could possibly be justified). A divine command theorist might therefore want to program the AI to do whatever God wants it to do.
Besides pointing being easier than describing, another potential advantage of such a moral realist approach might be that one is more confident in one’s meta-ethical view (“the pointer”) than in one’s object-level moral system (“one’s own description”). For example, someone could be confident that moral truth is determined by God’s will but be unsure that God’s will is expressed via the Bible, the Quran or something else, or how these religious texts are to be understood. Then that person would probably favor AI that cares about God’s will over AI that follows some particular interpretation of, say, the moral rules proposed in the Quran and Sharia.
A somewhat related issue which has received more attention in the moral realism literature is the convergence of human moral views. People have given moral realism as an explanation for why there is near-universal agreement on some ethical views (such as “when religion and tradition do not require otherwise, one shouldn’t torture babies”). Similarly, moral realism has been associated with moral progress in human societies, see, e.g., Huemer (2016). At the same time, people have used the existence of persisting and unresolvable moral disagreements (see, e.g., Bennigson 1996 and Sayre-McCord 2017, sect. 1) and the existence of gravely immoral behavior in some intelligent people (see, e.g., Nichols 2002) as arguments against moral realism. Of course, all of these arguments take moral realism to include a convergence thesis where being a human (and perhaps not being affected by some mental disorders) or a being a society of humans is sufficient to grasp and abide by moral truth.
Of course, there are also versions of moral realism that have even weaker (or just very different) implications for AI alignment and do not make any relevant convergence claims (cf. McGrath 2010). For instance, there may be moral realists who believe that there is a moral truth but that machines are in principle incapable of finding out what it is. Some may also call very different views “moral realism”, e.g. claims that given some moral imperative, it can be decided whether an action does or does not comply with that imperative. (We might call this “hypothetical imperative realism”.) Or “linguistic” versions of moral realism which merely make claims about the meaning of moral statements as intended by whoever utters these moral statements. (Cf. Lukas Gloor’s post on how different versions of moral realism differ drastically in terms of how consequential they are.) Or a kind of “subjectivist realism”, which drops mind-independence (cf. Olson 2014, ch. 2).
Why moral-realism-inspired research on AI alignment might be useful
I can think of many reasons why moral realism-based approaches to AI safety have not been pursued much: AI researchers often do not have a sufficiently high awareness of or interest in philosophical ideas; the AI safety researchers who do – such as researchers at MIRI – tend to reject moral realism, at least the versions with implications for AI alignment; although “moral realism” is popular among philosophers, versions of moral realism with strong implications for AI (à la Peter Singer or David Pearce) might be unpopular even among philosophers (cf. again Lukas’ post on how different versions of moral realism differ drastically in terms of how consequential they are); and so on…
But why am I now proposing to conduct such research, given that I am not a moral realist myself? The main reason (besides some weaker reasons like pluralism and keeping this blog interesting) is that I believe AI alignment research from a moral realist perspective might actually increase agreement between moral realists and anti-realists about how (and to which extent) AI alignment research should be done. In the following, I will briefly argue this case for the strong (à la Peter Singer and David Pearce) and the weak convergence versions of moral realism outlined above.
Strong versions
Like most problems in philosophy, the question of whether moral realism is true lacks an accepted truth condition or an accepted way of verifying an answer or an argument for either realism or anti-realism. This is what makes these problems so puzzling and intractable. This is in contrast to problems in mathematics where it is pretty clear what counts as a proof of a hypothesis. (This is, of course, not to say that mathematics involves no creativity or that there are no general purpose “tools” for philosophy.) However, the claim made by strong convergence moral realism is more like a mathematical claim. Although it is yet to be made precise, we can easily imagine a mathematical (or computer-scientific) hypothesis stating something like this: “For any goal X of some kind [namely the objectively incorrect and non-trivial-to-achieve kind] there is no efficient algorithm that when implemented in a robot achieves X in some class of environments. So, for instance, it is in principle impossible to build a robot that turns Earth into a pile of paperclips.” It may still be hard to formalize such a claim and mathematical claims can still be hard to prove or disprove. But determining the truth of a mathematical statement is not a philosophical problem, anymore. If someone lays out a mathematical proof or disproof of such a claim, any reasonable person’s opinion would be swayed. Hence, I believe that work on proving or disproving this strong version of moral realism will lead to (more) agreement on whether the “strong-moral-realism-based theory of AI alignment” is true.
It is worth noting that finding out whether strong convergence is true may not resolve metaphysical issues. Of course, all strong versions of moral realism would turn out false if the strong convergence hypothesis were falsified. But other versions of moral realism would survive. Conversely, if the strong convergence hypothesis turned out to be true, then anti-realists may remain anti-realists (cf. footnote 2). But if our goal is to make AI moral, the convergence question is much more important than the metaphysical question. (That said, for some people the metaphysical question has a bearing on whether they have preferences over AI systems’ motivation system – “if no moral view is more true than any other, why should I care about what AI systems do?”)
Weak versions
Weak convergence versions of moral realism do not make such in-principle-testable predictions. Their only claim is the metaphysical view that the goals identified by some method X (such as derivation from a set moral axioms, finding out what God wants, discourse, etc.) have some relation to moral truths. Thinking about weak convergence moral realism from the more technical AI alignment perspective is therefore unlikely to resolve disagreements about whether some versions of weak convergence moral realism are true. However, I believe that by not making testable predictions, weak convergence versions of moral realism are also unlikely to lead to disagreement about how to achieve AI alignment.
Imagine moral realists were to propose that AI systems should reason about morality according to some method X on the basis that the result of applying X is the moral truth. Then moral anti-realists could agree with the proposal on the basis that they (mostly) agree with the results of applying method X. Indeed, for any moral theory with realist ambitions, ridding that theory of these ambitions yields a new theory which an anti-realist could defend. As an example, consider Habermas’ discourse ethics and Yudkowsky’s Coherent Extrapolated Volition. The two approaches to justifying moral views seem quite similar – roughly: do what everyone would agree with if they were exposed to more arguments. But Habermas’ theory explicitly claims to be realist while Yudkowsky is a moral anti-realist, as far as I can tell.
In principle, it could be that moral realists defend some moral view on the grounds that it is true even if it seems implausible to others. But here’s a general argument for why this is unlikely to happen. You cannot directly perceive ought statements (David Pearce and others would probably disagree) and it is easy to show that you cannot derive a statement containing an ought without using other statements containing an ought or inference rules that can be used to introduce statements containing an ought. Thus, if moral realism (as I understand it for the purpose of this paper) is true, there must be some moral axioms or inference rules that are true without needing further justification, similar to how some people view the axioms of Peano arithmetic or Euclidean geometry. An example of such a moral rule could be (a formal version of) “pain is bad”. But if these rules are “true without needing further justification”, then they are probably appealing to anti-realists as well. Of course, anti-realists wouldn’t see them as deserving the label of “truth” (or “falsehood”), but assuming that realists and anti-realists have similar moral intuitions, anything that a realist would call “true without needing further justification” should also be appealing to a moral anti-realist.
As I have argued elsewhere, it’s unlikely we will ever come up with (formal) axioms (or methods, etc.) for morality that would be widely accepted by the people of today (or even among today’s Westerners with secular ethics). But I still think it’s worth a try. If it doesn’t work out, weak convergence moral realists might come around to other approaches to AI alignment, e.g. ones based on extrapolating from human intuition.
Other realist positions
Besides realism about morality, there are many other less commonly discussed realist positions, for instance, realism about which prior probability distribution to use, whether to choose according to some expected value maximization principle (and if so which one), etc. The above considerations apply to these other realist positions as well.
Acknowledgment
I wrote this post while working for the Foundational Research Institute, which is now the Center on Long-Term Risk.
1. There are some “universal instrumental goal” approaches to justifying morality. Some are based on cooperation and work roughly like this: “Whatever your intrinsic goals are, it is often better to be nice to others so that they reciprocate. That’s what morality is.” I think such theories fail for two reasons: First, there seem to many widely accepted moral imperatives that cannot be fully justified by cooperation. For example, we usually consider it wrong for dictators to secretly torture and kill people, even if doing so has no negative consequences for them. Second, being nice to others because one hopes that they reciprocate is not, I think, what morality is about. To the contrary, I think morality is about caring things (such as other people’s welfare) intrinsically. I discuss this issue in detail with a focus on so-called “superrational cooperation” in chapter 6.7 of “Multiverse-wide Cooperation via Correlated Decision Making”. Another “universal instrumental goal” approach is the following: If there is at least one god, then not making these gods angry at you may be another universal instrumental goal, so whatever an agent’s intrinsic goal is, it will also act according to what the gods want. The same “this is not what morality is about” argument seems to apply. ↩
2. Yudkowsky has written about why he now rejects this form of moral realism in the first couple of blog posts in the “Value Theory” series. ↩
I’ve written about the question of which decision theories describe the behavior of approaches to AI like the “Law of Effect”. In this post, I would like to discuss GOLEM, an architecture for a self-modifying artificial intelligence agent described by Ben Goertzel (2010; 2012). Goertzel calls it a “meta-architecture” because all of the intelligent work of the system is done by sub-programs that the architecture assumes as given, such as a program synthesis module (cf. Kaiser 2007).
Roughly, the top-level self-modification is done as follows. For any proposal for a (partial) self-modification, i.e. a new program to replace (part of) the current one, the “Predictor” module predicts how well that program would achieve the goal of the system. Another part of the system — the “Searcher” — then tries to find programs that the Predictor deems superior to the current program. So, at the top level, GOLEM chooses programs according to some form of expected value calculated by the Predictor. The first interesting decision-theoretical statement about GOLEM is therefore that it chooses policies — or, more precisely, programs — rather than individual actions. Thus, it would probably give the money in at least some versions of counterfactual mugging. This is not too surprising, because it is unclear on what basis one should choose individual actions when the effectiveness of an action depends on the agent’s decisions in other situations.
The next natural question to ask is, of course, what expected value (causal, evidential or other) the Predictor computes. Like the other aspects of GOLEM, the Predictor is subject to modification. Hence, we need to ask according to what criteria it is updated. The criterion is provided by the Tester, a “hard-wired program that estimates the quality of a candidate Predictor” based on “how well a Predictor would have performed in the past” (Goertzel 2010, p. 4). I take this to mean that the Predictor is judged based the extent to which it is able to predict the things that actually happened in the past. For instance, imagine that at some time in the past the GOLEM agent self-modified to a program that one-boxes in Newcomb’s problem. Later, the agent actually faced a Newcomb problem based on a prediction that was made before the agent self-modified into a one-boxer and won a million dollars. Then the Predictor should be able to predict that self-modifying to one-boxing in this case “yielded” getting a million dollar even though it did not do so causally. More generally, to maximize the score from the Tester, the Predictor has to compute regular (evidential) conditional probabilities and expected utilities. Hence, it seems that the EV computed by the Predictor is a regular EDT-ish one. This is not too surprising, either, because as we have seen before, it is much more common for learning algorithms to implement EDT, especially if they implement something which looks likethe Law of Effect.
In conclusion, GOLEM learns to choose policy programs based on their EDT-expected value.
Acknowledgements
This post is based on a discussion with Linda Linsefors, Joar Skalse, and James Bell. I wrote this post while working for the Foundational Research Institute, which is now the Center on Long-Term Risk.